Guide
Achieving ClusterMAX Gold with vCluster
How AI Cloud Providers Reach ClusterMAX Gold in 90 Days
SemiAnalysis evaluated 84 GPU cloud providers in the 2025 ClusterMAX round. Seven reached Gold or above. The rest are largely interchangeable to enterprise AI buyers, which is the practical effect of the rating: it determines whether an AI cloud gets seriously evaluated for production training and inference workloads. The rating shows up in procurement conversations, in contract negotiation, and in the press cycle every time a new round publishes.
Moving up the rankings, and reaching Gold, is about more than hardware. The criteria reviewers grade against, tenant isolation, self-service orchestration, lifecycle automation, per-tenant observability, are the operational primitives of a managed cloud. An AI cloud that sells raw GPU hours and provisions environments by ticket cannot reach the higher medallions regardless of how fast the silicon is. The work of climbing is the work of operating like a cloud.
vCluster is the platform layer that closes that gap. It gets an AI cloud to a Gold-capable state in weeks rather than the year-plus it would take to build the equivalent in-house. ClusterMAX names vCluster directly in the criteria: the Security criterion language is verbatim "vCluster or similar isolation beyond container-based only," which means an AI cloud running vCluster meets the criterion by name.
Before any of the criteria conversation matters, an AI cloud has to answer one question: are we going to build managed Kubernetes ourselves, or are we going to buy the stack. SemiAnalysis is direct about the cost of the build path: "Anyone can cobble together open-source components to hit Underperform, but moving beyond Bronze takes months of engineering effort, and Platinum can take years." The answer determines whether a ClusterMAX rating is a 12-month project or a 90-day rollout, and whether your platform team is the one designing tenant isolation primitives from scratch or the one shipping customer-facing features.
What building looks like in practice. A typical from-scratch managed Kubernetes service for AI workloads runs roughly as follows, based on the work patterns of AI clouds who have done it.
| Platform capability | Engineers needed | Time to build |
|---|---|---|
| Bare metal provisioning and PXE automation | 2 to 3 infra engineers | 3 to 4 months |
| Network automation and tenant isolation | 1 to 2 networking engineers | 2 to 3 months |
| Kubernetes cluster orchestration | 2 to 3 platform engineers | 3 to 6 months |
| Per-tenant compute infrastructure with isolation | 2+ platform engineers | 4 to 6 months |
| Platform integrations (NVIDIA stack, Run:AI, Ray, SLURM) | 1 to 2 engineers | 2 to 3 months |
Totals across a realistic team: 6 to 10 platform engineers, 6 to 12 months, $1M+ in engineering cost before customer-facing features are built. And that estimate assumes the team has the experience to design these primitives correctly the first time. Most do not, which adds rework.
The hidden cost: GPU depreciation during the build. A $10 million GPU cluster generating $2 to $3 per GPU hour loses millions in potential revenue for every month the platform launch slips. The cost is invisible until it is too late, because it is not a line item in the engineering plan. It is the gap between when the hardware arrives and when the platform can sell it.
The operating economics, side by side. The build path produces a fleet of physical clusters that scales operationally with tenant count. The buy path produces a single control plane cluster with lightweight tenant clusters that scale sublinearly.
| Metric | Building managed Kubernetes per tenant | With vCluster |
|---|---|---|
| 50-tenant footprint | 50 physical clusters | 1 control plane cluster + 50 tenant clusters |
| Platform engineers required | 8 to 15, scales linearly with tenants | 3 to 5, scales sublinearly |
| Tenant provisioning time | Hours to days | Minutes via API |
| GPU utilization | 30% to 45%, static allocation per cluster | 60% to 75%, dynamic allocation across tenant clusters |
| Control plane footprint | 50 full etcd + API server + scheduler stacks | 1 control plane cluster + lightweight per-tenant control planes |
| Upgrade complexity | 50 independent upgrade cycles | Per-tenant rolling upgrades from a single platform |
| Blast radius of failure | One cluster impact, but 50 to operate and monitor | One tenant cluster impact, centralized monitoring |
What buying vCluster looks like. vCluster, vNode, and vMetal together cover the bare metal, tenant isolation, and orchestration layers of the table above. The remaining work, platform integrations and customer-facing features, is what differentiates one AI cloud from another and is where the team's time should actually go.

vCluster runs in production across more than 100,000 GPUs and 40 million tenant clusters spun up lifetime, including multiple NVIDIA Cloud Partners. Boost Run, an NVIDIA Preferred Cloud Service Provider valued at $614M post-merger, launched a production managed Kubernetes service in under 45 days with no new platform engineering hires. Nscale (NVIDIA Cloud Partner, $3.8B+ funded, 100,000+ GPUs planned) runs vCluster on a bare-metal underlay with InfiniBand and RDMA and provisions a customer-ready AI cluster in two minutes. Polarise, a European NVIDIA Cloud Partner, delivers AI Factories across Europe on vCluster with full data residency enforced at the infrastructure layer. CoreWeave has been a design partner since 2022; Brian Venturo, CSO at CoreWeave, calls vCluster "the first proven solution for operationalizing virtual Kubernetes clusters at scale."
Buying makes sense for any AI cloud that cannot dedicate 8 to 10 platform engineers for a year and absorb the GPU depreciation cost of the build window. The rest of this guide is written for that path.
Five moves, ranked by effort-to-impact, that together produce a platform capable of earning a Gold rating. Each maps to specific ClusterMAX criteria and includes a realistic time estimate.
| # | Move | Effort | Primary criteria lifted |
|---|---|---|---|
| 1 | Self-service tenant clusters via vCluster Platform | 2 to 3 weeks | Security, Orchestration, Monitoring |
| 2 | vNode for kernel-level workload isolation | 1 to 2 weeks | Security (depth) |
| 3 | Private Nodes as the production architecture | 2 to 3 weeks | Reliability, Networking, Security |
| 4 | vMetal for bare metal lifecycle | 30 to 60 days | Lifecycle, Reliability, Monitoring |
| 5 | Network automation via Netris | 2 to 4 weeks | Networking, Security |
Move 1. Stand up self-service tenant clusters as the default customer experience.

What to build. Deploy vCluster Platform in HA mode (3 replicas) backed by external Postgres. Configure OIDC against your customer identity provider at install time. Define one tenant cluster template (Kubernetes 1.29 or 1.30, GPU Operator pre-installed, kube-prometheus and DCGM exporter baked in). Expose the provisioning API behind your customer portal so a new signup results in a tenant cluster within minutes and a kubeconfig delivered automatically.
What this lifts on the rubric. Security (vCluster is explicitly named in the criteria as a tenant isolation approach beyond container-based only). Orchestration (self-service replaces ticket-driven provisioning). Monitoring (per-tenant observability ships in the default template).
Effort. 1 week for pilot, 2 to 3 weeks for production rollout to first 10 tenants. Boost Run did the entire path in under 45 days.
Reviewer evidence. kubectl --kubeconfig customer.yaml get nodes returns only that customer's nodes. kubectl get pods -A from inside the tenant cluster shows no platform-level kube-system agents.
Move 2. Layer vNode for kernel-level workload isolation.
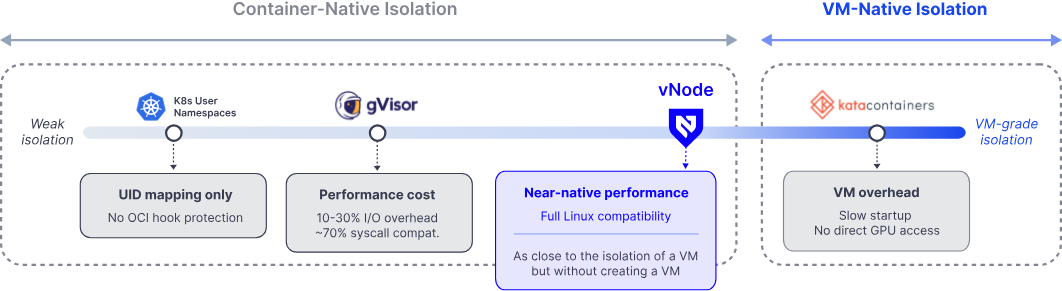
What to build. Deploy vNode as the container runtime on tenant nodes. vNode uses Linux user namespaces to remap container UIDs to unprivileged host UIDs, combined with seccomp profiles and cgroup separation, to contain container escape vulnerabilities to the affected workload. No VMs, no syscall interception, no hypervisor overhead. Run in parallel with Move 1.
What this lifts on the rubric. Security (depth). The ClusterMAX criteria flag container isolation alone as insufficient and require protection against container escalation. vNode is the answer, with an independent third-party assessment (Cure53, September 2025) confirming no container escapes during a 30-day, 7-researcher engagement.
Effort. 1 to 2 weeks, in parallel with Move 1.
Reviewer evidence. A workload that escapes the container lands as an unprivileged host user (UID 100000+) with no access to other tenants' processes, files, or network. The Cure53 assessment report is referenceable directly in the security section of the rating submission.
Move 3. Adopt Private Nodes as the production architecture.
What to build. Use Private Nodes so that tenant workloads run only on hardware dedicated to that tenant. GPU hardware is allocated exclusively per tenant, with full data plane isolation between tenants. This is the production architecture every NVIDIA Cloud Partner running vCluster uses today, including Boost Run, Corvex, and Nscale.
What this lifts on the rubric. Reliability (blast radius containment per tenant, hardware-level). Networking (cleaner per-tenant network attachment). Security (the hardware boundary closes the last shared-kernel surface).
Effort. 2 to 3 weeks if a Terraform provider exists for the underlying hardware. We have validated this on GCP, AWS, Proxmox, and others. Hardware platforms without a Terraform provider need a custom integration, which the architecture review scopes.
Reviewer evidence. kubectl get nodes from inside Tenant A's cluster returns only nodes physically allocated to that tenant. Tenant B's workloads share no kernel surface, no hardware, no data plane.
Move 4. Automate the bare metal lifecycle with vMetal.

What to build. Deploy vMetal to handle PXE boot, driver installation (NVIDIA, CUDA, kernel modules), burn-in test gating, DCGM and IPMI integration, and XID and SXID error detection wired to drain-replace-validate workflows. Run new hardware through vMetal as it arrives; migrate existing fleet in waves.
What this lifts on the rubric. Lifecycle (end-to-end automation replacing manual scripts). Reliability (mechanical failure handling). Monitoring (fleet-side telemetry).
Effort. 30 to 60 days for production rollout. Work runs in parallel with the earlier moves.
Reviewer evidence. A simulated XID error triggers automated drain of the affected node, replacement from the available pool, burn-in validation, and return to service without an engineer in the loop.
Move 5. Wire network automation into the tenant lifecycle.

What to build. Hook network provisioning into tenant cluster create and destroy events. When a new tenant cluster is provisioned, network segment assignment, PKey configuration on InfiniBand, VLAN tags on RoCE, NCCL configuration, and SR-IOV setup happen automatically. We recommend Netris as the network automation partner here. AI clouds running their own network automation stack can integrate at the same hooks.
What this lifts on the rubric. Networking (the criterion with the highest absolute bar). Security (network isolation between tenants).
Effort. 2 to 4 weeks for a Netris integration on a typical fabric. NCCL benchmark validation on 4 nodes is the acceptance test.
Reviewer evidence. NCCL all-reduce benchmark on a new tenant cluster passes spec on the first run, with no manual fabric configuration.
Moves 1, 2, and 3 are achievable in the first 30 days and produce a working managed Kubernetes service with tenant isolation, self-service, and per-tenant observability. Moves 4 and 5 complete the lifecycle and networking story over the following 60 days. By day 90, the platform is Gold-capable across the criteria that vCluster covers.
ClusterMAX defines 142 individual criteria across ten categories. vCluster directly addresses 78 of them, another 9 are on the product roadmap, and the remaining 55 are operator-layer decisions, hardware procurement, geographic footprint, fabric tuning, compliance certifications, that no platform vendor can deliver for the AI cloud. The full per-criterion scorecard with all 142 line items is available at vcluster.com/clustermax.
| # | Category | Coverage |
|---|---|---|
| 1 | Security | 9 of 19 (47%) |
| 2 | Lifecycle | 15 of 16 (94%) |
| 3 | Orchestration | 16 of 17 (94%) |
| 4 | Storage | 6 of 14 (43%) |
| 5 | Networking | 4 of 10 (40%) |
| 6 | Reliability | 22 of 24 (92%) |
| 7 | Monitoring | 10 of 14 (71%) |
| 8 | Pricing | 2 of 7 (29%) |
| 9 | Partnerships | 3 of 6 (50%) |
| 10 | Availability | 1 of 9 (11%) |
Dedicated control plane and worker nodes per tenant, kernel-level isolation via vNode, automated network isolation at provisioning.
| What ClusterMAX grades | What vCluster delivers | Coverage |
|---|---|---|
| Tenant isolation at the control plane, the workload runtime, and the network. The criteria explicitly name "vCluster or similar isolation beyond container-based only." | Each tenant gets their own Kubernetes API server, etcd, RBAC, and CRDs (Move 1). Workloads run with kernel-level user namespace isolation via vNode (Move 2), independently verified by Cure53. Network isolation is automated per tenant via Netris hooks (Move 5). High-security tiers can deploy the tenant control plane in a dedicated VM rather than as a pod. | 9 of 19 (47%). vCluster is the named pattern under the gating Security criterion, which is satisfied regardless of the overall category coverage rate. |
Tiering pattern. Most production AI clouds offer three tiers: Standard (tenant control plane as pod, shared nodes, default runtime), Enhanced (pod control plane, Private Nodes, vNode runtime), and Enterprise (VM-based control plane, Private Nodes, vNode runtime). The tier model maps to a good/better/best pricing structure the AI cloud can market directly.
Production-ready tenant GPU clusters via vCluster Templates. GPU Operator, MOFED, and driver stack deployed fleet-wide.
| What ClusterMAX grades | What vCluster delivers | Coverage |
|---|---|---|
| How new hardware enters service, how failures are detected and remediated, how new GPU SKUs are added to the catalog, how nodes are decommissioned at end of life. | vMetal (Move 4) handles PXE boot, driver installation, burn-in test gating, DCGM and IPMI telemetry, XID and SXID error detection wired to drain-replace-validate workflows, and node decommissioning. Rack-to-available time drops from days to hours. New GPU SKUs (H200, B200, GB200) are added as profiles rather than bespoke integrations. | 15 of 16 (94%) |
Self-service Kubernetes: kubeconfig at provisioning, SSO and RBAC isolated per tenant, GPU device assignment automatic.
| What ClusterMAX grades | What vCluster delivers | Coverage |
|---|---|---|
| Time from customer signup to first workload running. Self-service environments score highly; manual handoffs lose points. | A customer signup calls the vCluster Platform API. A tenant cluster is provisioned in minutes with an OIDC-backed kubeconfig delivered automatically, GPU Operator pre-installed, RBAC and resource quotas pre-configured (Move 1). Time to first workload is measured in minutes, not days. | 16 of 17 (94%) |
PVC, hostPath, and S3 work natively. Automated backups with configurable retention. VolumeSnapshot support built in.
| What ClusterMAX grades | What vCluster delivers | Coverage |
|---|---|---|
| Parallel filesystem integration (Weka, DDN, VAST), CSI driver correctness, the storage tier options exposed to tenants. | CSI passthrough is clean and tenants see standard PersistentVolumeClaim semantics. Whatever storage classes the control plane cluster exposes are available inside tenant clusters. The storage tier itself is a vendor relationship the AI cloud has directly with Weka, DDN, or VAST. | 6 of 14 (43%). Non-addressed criteria are operator scope: storage vendor selection and parallel-filesystem hardware investment. |
InfiniBand and RoCEv2 fabric automation via Netris. SHARP collective operations supported. Zero overhead on the MPI and NCCL data path.
| What ClusterMAX grades | What vCluster delivers | Coverage |
|---|---|---|
| NCCL benchmark performance, VLAN isolation between tenants on RoCEv2 fabrics, PKey configuration on InfiniBand, GID index correctness, SHARP-aware topology, SR-IOV configuration. | Network automation hooks into tenant cluster create and destroy events (Move 5). With Netris as the partner, BGP-based IP fabric, automated VLAN isolation, PKey configuration on InfiniBand, NCCL settings, and SR-IOV setup happen automatically per tenant. NCCL benchmarks pass spec on the first run. Any network automation platform with an API and tenant lifecycle hooks can substitute for Netris. | 4 of 10 (40%). Non-addressed criteria are largely fabric-tuning and hardware-investment scope. |
GPU health via DCGM: XID, ECC, thermal, PCIe, NVLink monitored per tenant. InfiniBand fabric health via Netris-UFM integration.
| What ClusterMAX grades | What vCluster delivers | Coverage |
|---|---|---|
| Blast radius containment when a tenant misbehaves, mean time to recover from node failure, control plane uptime, ability to roll upgrades without affecting the broader platform. | Per-tenant control plane isolation (Move 1) contains blast radius; a tenant cluster failure does not affect any other tenant. vMetal-driven mechanical recovery (Move 4) handles node failures without an engineer in the loop. Upgrades roll per-tenant rather than fleet-wide, so the platform stays available while individual tenants are upgraded on their own schedule. | 22 of 24 (92%) |
Multi-tenant observability stack based on Grafana and Prometheus. Validated dashboards for GPU and control plane metrics.
| What ClusterMAX grades | What vCluster delivers | Coverage |
|---|---|---|
| Provider-facing fleet observability and customer-facing per-tenant observability (GPU utilization, ECC error rates, thermal data, workload metrics). | The default tenant cluster template ships with kube-prometheus, Grafana, and the DCGM exporter inside the tenant cluster (Move 1). The customer sees their own metrics through their own Grafana endpoint with no window into the fleet. The provider-facing fleet view runs on the control plane cluster, consuming vMetal telemetry and tenant cluster health signals. | 10 of 14 (71%) |
Per-tenant usage metering and showback via DCGM and Prometheus. Reduces operations overhead, fewer engineers per customer at scale.
| What ClusterMAX grades | What vCluster delivers | Coverage |
|---|---|---|
| $/GPU/hour competitiveness, transparency of pricing tiers, the ability to deliver showback or chargeback to customers. | Per-tenant resource accounting is built into vCluster Platform. Customers see their own usage in near-real-time. Chargeback exports can feed external billing platforms like Metronome. | 2 of 7 (29%). $/GPU/hour and pricing-tier decisions are operator scope; the platform reduces overhead but does not set price. |
Full CNCF ecosystem compatibility. GPU Operator, DCGM, and IB/RoCEv2 stack enable NCP technical requirements for operators.
| What ClusterMAX grades | What vCluster delivers | Coverage |
|---|---|---|
| NVIDIA partnerships, validated reference architectures, ecosystem certifications (NCP, DGX-Ready). | Full compatibility with the NVIDIA ecosystem (GPU Operator, NIM, AI Enterprise, NCCL, DCGM, MIG, fractional GPU). Reference deployments at scale across multiple NVIDIA Cloud Partners: CoreWeave, Nscale, Boost Run, Corvex, Polarise, Nebius. | 3 of 6 (50%). Formal NVIDIA certifications (NCP, DGX-Ready) remain partnerships the AI cloud completes directly with NVIDIA. |
Hardware-agnostic provisioning: H100, H200, B200, GB200 NVL72 all register without platform changes via vMetal.
| What ClusterMAX grades | What vCluster delivers | Coverage |
|---|---|---|
| Total GPU count, regional footprint, how fast new capacity comes online when demand rises. | vCluster Platform's single control plane gives operators fleet-wide capacity visibility across hundreds of tenant clusters running on one control plane cluster, the capability reviewers grade directly under capacity planning. vMetal accelerates the rack-to-available pipeline (Move 4), so newly delivered hardware is sellable in hours rather than days. | 1 of 9 (11%). Total GPU count, regional footprint, and capacity availability are operator-scope hardware procurement decisions. |
The sequence below assumes Private Nodes as the target architecture (the production standard in use at every NVIDIA Cloud Partner running vCluster today), Netris as the network automation partner (substitutable), and vMetal rolling in parallel with the upper-layer work.
Days 0 to 30. Stand up the self-service tenant cluster experience.
Stand up the vCluster Platform in HA mode with external Postgres. Configure OIDC against the AI cloud's customer identity provider. Define the default tenant cluster template (Kubernetes 1.29 or 1.30, GPU Operator, kube-prometheus, DCGM exporter, vNode runtime). Wire the customer portal to the provisioning API.
Outcome by day 14: pilot tenant clusters running on the new platform. A test customer can self-provision and run their first workload.
Outcome by day 30: production rollout to the first wave of tenants. Self-service onboarding is the default customer experience. Security, Orchestration, and Monitoring scores move visibly against the rubric. This is the milestone Boost Run hit in under 45 days from decision to first paying customer.
Days 30 to 60. Move to dedicated hardware and start bare metal automation.
Stand up Private Nodes for the production tier. Begin vMetal rollout for new hardware deliveries. Wire network automation hooks (Netris or equivalent) into tenant cluster lifecycle events. Validate NCCL benchmarks on the new pattern.
Outcome by day 60: Reliability and Networking scores improving. New hardware coming online through vMetal rather than manual scripts. The next tier of customers (the ones with stricter isolation requirements) can move to Private Nodes.
Days 60 to 90. Close the loop and prepare for review.
Complete vMetal rollout across the existing fleet. Validate NCCL benchmarks end-to-end. Build the case study and reviewer-facing materials that document the new platform capabilities. Engage SemiAnalysis or another reviewer for the first formal evaluation.
Outcome by day 90: Gold-capable platform. Reliability, Lifecycle, and Monitoring scores meaningfully above peer providers. First formal review can be scheduled.
A note on what comes after day 90. Holding a Gold rating over time requires sustaining the operational discipline this rollout introduces. The two non-platform projects that often lag, compliance certification (SOC 2, ISO 27001) and parallel filesystem performance audits, should start in parallel during this window so they are ready when the rating review happens.
ClusterMAX is a Kubernetes infrastructure rating framework published by SemiAnalysis. It grades AI cloud providers across ten dimensions: Security, Lifecycle, Orchestration, Storage, Networking, Reliability, Monitoring, Pricing, Partnerships, and Availability. Ratings range from Bronze to Platinum, with Gold marking a provider that meets enterprise AI infrastructure expectations.
SemiAnalysis publishes ClusterMAX as part of its public research on AI infrastructure providers. The rubric is openly available at clustermax.ai and gets cited in procurement evaluations, contract negotiations, and the press cycle for the AI cloud category.
ClusterMAX grades ten dimensions of an AI cloud provider's Kubernetes platform: tenant isolation security, hardware lifecycle automation, orchestration speed, parallel filesystem storage integration, GPU fabric networking, blast-radius reliability, per-tenant observability, pricing transparency, NVIDIA ecosystem partnerships, and capacity availability. The platform layer determines roughly half of the criteria; hardware procurement, fabric tuning, and compliance certifications determine the rest.
Most AI clouds running vCluster reach a Gold-capable platform in 60 to 90 days. Boost Run, an NVIDIA Preferred Cloud Service Provider, went from decision to first paying customer in under 45 days with no new platform engineering hires. Across the customer base, vCluster runs in production on more than 100,000 GPUs with 40 million+ tenant clusters spun up lifetime.
A tenant cluster gives each customer their own Kubernetes API server, etcd, RBAC, and CRDs. The tenant sees only their own workloads and nodes via kubectl. Namespace isolation puts all tenants on one cluster with a shared API server and control plane, and tenants can typically enumerate cluster-wide resources and see platform internals. ClusterMAX explicitly flags namespace-based isolation as insufficient for AI cloud production use.
No. vCluster runs on top of any conformant Kubernetes distribution: RKE2, EKS, GKE, AKS, BCM Kubernetes, k0s, or vanilla upstream. AI clouds adopting vCluster do not rip out existing platform infrastructure; vCluster adds the tenant isolation and lifecycle layer above whatever base Kubernetes is already in production.
Yes. vCluster runs in production on bare-metal GPU infrastructure with InfiniBand and RoCE fabrics at multiple NVIDIA Cloud Partners, including Nscale (100,000+ GPUs planned), Boost Run, Corvex, and Polarise. Tenant workloads run on bare metal with no virtualization layer in the data path, preserving native NCCL and RDMA performance.
Yes. vCluster's core is open source and available on GitHub at github.com/loft-sh/vcluster. vCluster Platform, vNode, and vMetal are the commercial layers that add multi-cluster management, kernel-level workload isolation, and bare-metal lifecycle automation respectively. The open source core gives operators a continuity path if commercial terms change.
Multiple NVIDIA Cloud Partners run vCluster in production today, including Nscale, Boost Run, Corvex, Polarise, and Nebius. Other production deployments include Lintasarta (Indonesia's leading GPU cloud), QumulusAI, Nebul (European sovereign AI cloud), and CoreWeave (design partner since 2022). The customer base spans 100,000+ GPUs and 40 million+ tenant clusters spun up lifetime. Most run vCluster Standalone as the tenant control plane cluster, with vCluster Platform layered on top for multi-tenant management.
Every AI cloud has specific questions about their fabric, their hardware, their tenant model, and their integration points that no general document can fully answer. The fastest way to translate the moves above into an actionable plan is an architecture review.
Architecture review. A 60 to 90 minute session with the AI cloud's platform engineering team and a vCluster Labs solutions architect. Walks through the current state, the gaps against the ClusterMAX rubric, and produces a fitted version of the 90-day rollout plan tailored to the environment. Typical output: a written plan the platform team can take to their leadership and the procurement function for approval.
Pilot scope. Most pilots run for 4 to 6 weeks against a slice of the existing fleet. The pilot produces a working tenant cluster running vCluster, vNode, observability, and (where applicable) Netris-integrated network automation, plus a measurement plan covering the ClusterMAX dimensions where the platform moves the score. Pilots typically include direct Slack support with our engineering team.
Support coverage. Production AI clouds running vCluster get a named technical account team and direct Slack access for debugging and incident response. The institutional knowledge baked into our support comes from the largest deployed AI cloud footprint in the industry, which materially shortens the path from issue to fix during a rating review window.
Pricing. Pricing for AI clouds is structured around GPU count and tenant cluster volume rather than seats. The account team walks through the model during the architecture review.
Scope. vCluster, vNode, and vMetal cover the bulk of the work that gets an AI cloud to a medallion rating. The categories outside the platform's scope, compliance certification, hardware procurement, fabric performance tuning, parallel filesystem performance, $/GPU/hour competitiveness, are work the AI cloud completes directly. The architecture review identifies which of these is most likely to be the binding constraint and recommends sequencing.
Next steps. Book a demo at vcluster.com/enterprise-demo, or read the full ClusterMAX criteria coverage at vcluster.com/clustermax.
Deploy your first virtual cluster today.
