Guide
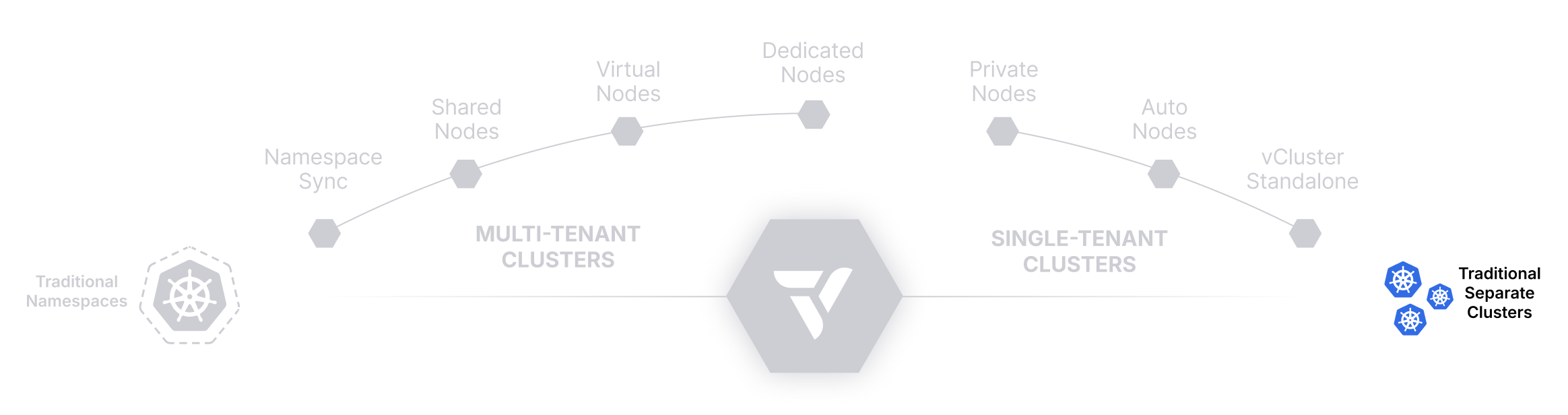
Tenancy Models with vCluster
The Ultimate Guide to Kubernetes Isolation
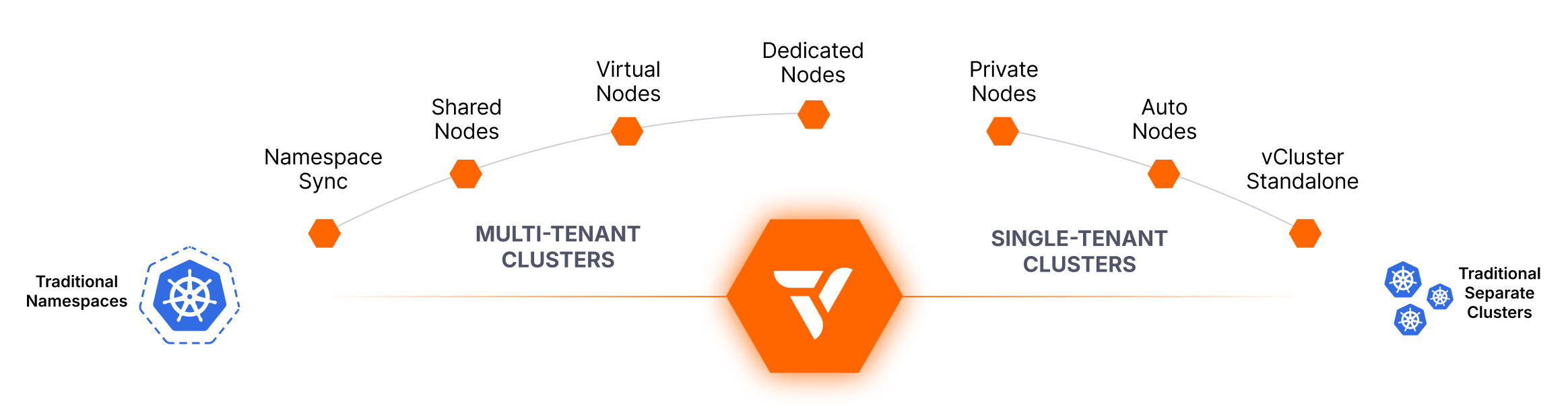
Modern platform teams need to support fast-moving engineering orgs while controlling cloud costs, ensuring workload security, and maintaining operational sanity. But Kubernetes doesn’t make multi-tenancy easy.
This guide breaks down the core tenancy models supported by vCluster—from lightweight namespace-based approaches to fully isolated per-tenant environments—and introduces platform-level capabilities like Auto Nodes that help you scale infrastructure intelligently.
Whether you’re running dev/test clusters, multi-tenant SaaS workloads, or GPU-intensive training pipelines, this guide can help you choose the right isolation strategy for every team, environment, or use case. Let’s get started!
Use Native Namespaces for Multi-Tenancy — Fast but Limited in Scope
Lightweight and simple, but lacks strong isolation. Ideal for small teams or environments where security boundaries aren’t a concern.
Kubernetes namespaces are the most basic and widely used model for multi-tenancy. Each team or tenant is assigned a unique namespace within a shared cluster. Platform teams can apply RBAC rules, network policies, and resource quotas to help segment access and limit usage within each namespace.
While this approach is quick to set up and uses only core Kubernetes primitives, it lacks any form of control plane or API isolation. All tenants share the same scheduler, CRDs, node pool, and cluster-wide configurations. As a result, namespaces are prone to issues like CRD conflicts, noisy neighbors, and accidental cross-tenant impacts—making them unsuitable for production-grade multi-tenancy at scale.
Namespaces logically divide a Kubernetes cluster into smaller, scoped environments using native Kubernetes objects. Each tenant receives a namespace, and optional policies are layered on top:
All tenants continue to use the same underlying control plane, scheduler, node pool, and extensions. Cluster-wide resources like CRDs and webhooks are still global, and a misconfigured tenant can easily impact others.
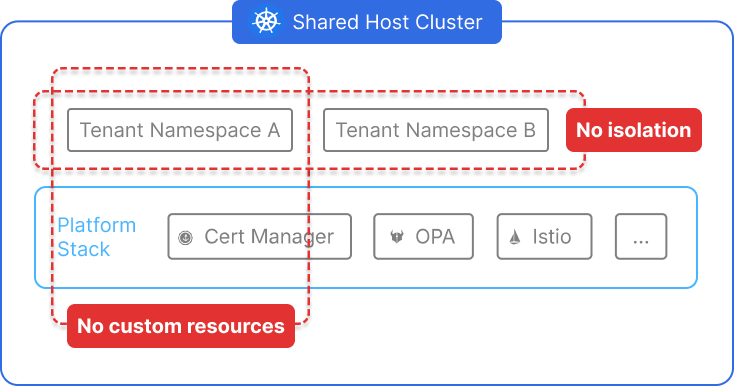
These limitations make traditional namespaces a poor fit for environments with strong isolation, customization, or scalability requirements.
Sync Tenant Namespaces to a Virtual Cluster — Lightweight Isolation, No Infrastructure Changes
Bring existing namespaces under vCluster management without disrupting workloads or provisioning new clusters.
Namespace Syncing allows you to connect existing Kubernetes namespaces from the host cluster to a virtual cluster, making it one of the fastest and most flexible ways to adopt vCluster without changing how workloads are deployed. This approach lets you treat an existing namespace as a fully isolated virtual cluster from an access, API, and control perspective—without relocating workloads or provisioning additional infrastructure.
With Namespace Syncing, platform teams can gradually migrate to vCluster without impacting running workloads. Tenants gain virtual cluster benefits like isolated API access, scoped RBAC, and custom CRDs, while underlying compute remains shared and existing namespace-level policies stay in place.
When a vCluster is created with namespace syncing enabled, it establishes a logical connection between a namespace in the host cluster and the virtual cluster’s control plane. All Kubernetes resources created within the virtual cluster are automatically synced into the specified namespace on the host cluster.
The synced namespace continues to use the host’s node pool, network infrastructure, and storage. However, tenants interact with the virtual cluster as if it were a dedicated environment—with their own CRDs, RBAC policies, service accounts, and access controls—enforced by the vCluster layer.
Namespace Syncing offers a strong improvement over traditional namespaces, but it still inherits some of the same infrastructure-level limitations.
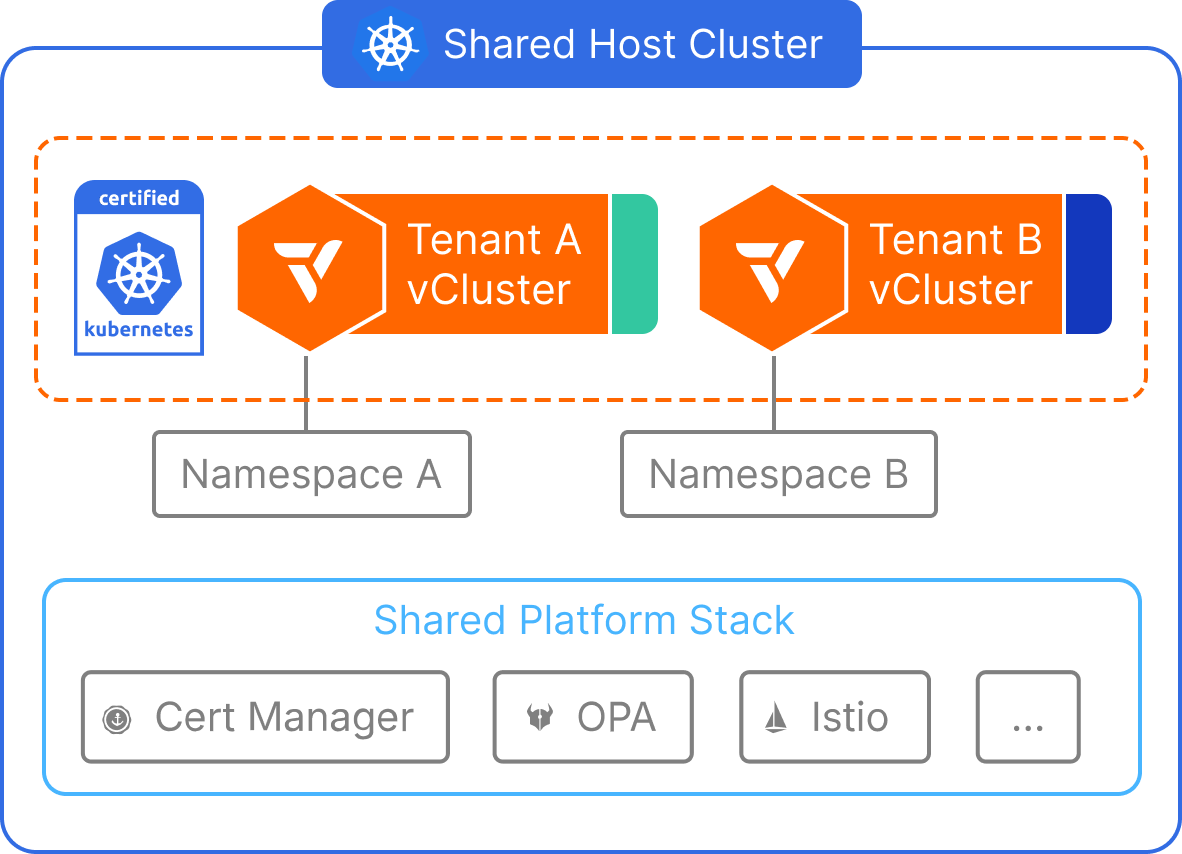
Run Virtual Clusters on Shared Nodes — Maximize Density, Minimize Waste
Best for efficient compute usage across multiple virtual clusters, especially in dev/test environments.
The Shared Nodes tenancy model allows multiple virtual clusters to run workloads on the same physical Kubernetes nodes. This configuration is ideal for scenarios where maximizing resource utilization is a top priority—especially for internal developer environments, CI/CD pipelines, and cost-sensitive use cases.
Each virtual cluster has its own isolated control plane, API server, and CRDs, but workloads are scheduled without node-level isolation. This setup helps platform teams deliver the benefits of vCluster (like per-tenant customization and faster provisioning) while minimizing infrastructure costs by sharing underlying compute across all tenants.
All virtual clusters run in a single Kubernetes host cluster and schedule pods onto the same shared node pool. The vCluster control plane enforces separation at the API, RBAC, and CRD levels, but does not restrict pod scheduling unless additional mechanisms (e.g., taints, affinities) are applied.
Tenants interact with their own virtual clusters as if they are separate environments, but their workloads run side-by-side with those from other vClusters at the node level. Shared infrastructure components like the container runtime, CNI, and CSI drivers are used across all tenants.
This model is best when speed and density matter more than strict isolation guarantees.
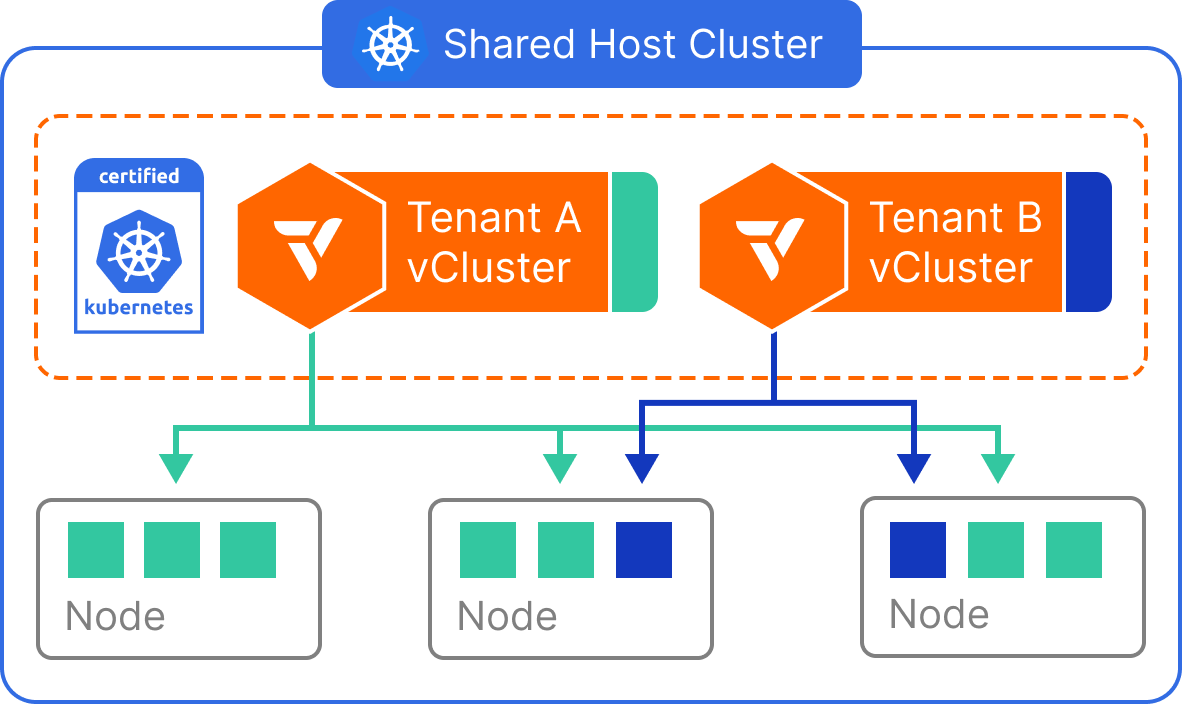
Enforce Tenant Boundaries at the Node Level — Without Dedicating Physical Infrastructure
Virtualizes node boundaries for enhanced security and separation inside a shared cluster.
Virtual Nodes provide an effective way to isolate tenant workloads without allocating dedicated physical nodes per tenant. This model leverages virtualization at the node level—through vNode—to create strong scheduling boundaries while continuing to share the underlying infrastructure.
Each virtual cluster receives its own control plane and interacts with a virtualized view of the node environment. Workloads are scheduled into tenant-scoped virtual nodes, which are translated into actual pods on the shared cluster. This allows teams to achieve node-level isolation semantics, including taints and tolerations, without managing separate node pools.
Virtual Nodes are implemented within vCluster by inserting a translation layer between the virtual control plane and the physical cluster. From the perspective of a tenant, the vCluster presents one or more virtual nodes, each representing a safe, scoped execution environment.
Internally, workloads from these virtual nodes are scheduled as regular pods on shared physical nodes, but the tenant does not see or interact with the real underlying node environment. This abstraction enables stronger isolation, enforces placement boundaries, and prevents tenants from seeing or interacting with each other’s workloads—even though compute is technically shared.
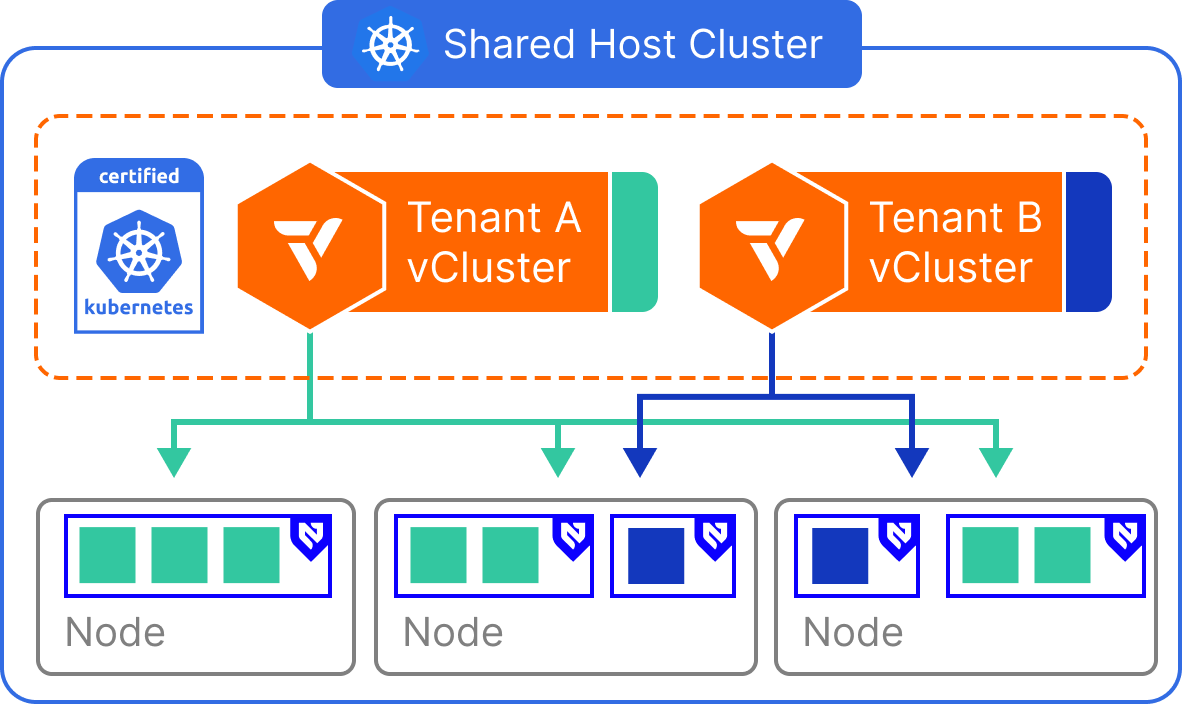
This tenancy mode is ideal when you need workload separation but want to avoid operational and cost overhead from dedicated infrastructure.

Assign Virtual Clusters to Specific Node Pools — Dedicated Compute Without Cluster Sprawl
Provides node-level compute separation by targeting labeled node groups within a shared cluster.
Dedicated Nodes allow platform teams to give each virtual cluster exclusive access to a set of physical nodes—without having to provision entirely separate clusters. By combining vCluster’s multi-tenant architecture with Kubernetes node selectors, workloads from each virtual cluster can be scoped to a specific group of labeled nodes, ensuring compute separation across tenants.
This approach enables strong operational boundaries and predictable performance, while maintaining all the benefits of shared infrastructure. It’s especially effective for teams who want dedicated compute for certain tenants, environments, or workloads—without duplicating every part of the platform stack.
Each vCluster is configured with a Kubernetes nodeSelector (or affinity rules) that ensures all tenant workloads are scheduled only to nodes with specific labels. For example, a virtual cluster assigned to nodegroup=tenant-a will only run pods on nodes matching that label.
While compute is scoped to these dedicated nodes, all other components—like the CNI, CSI, and underlying Kubernetes host cluster—remain shared. The vCluster itself maintains full API isolation, separate CRDs, tenant-specific RBAC, and control plane security.
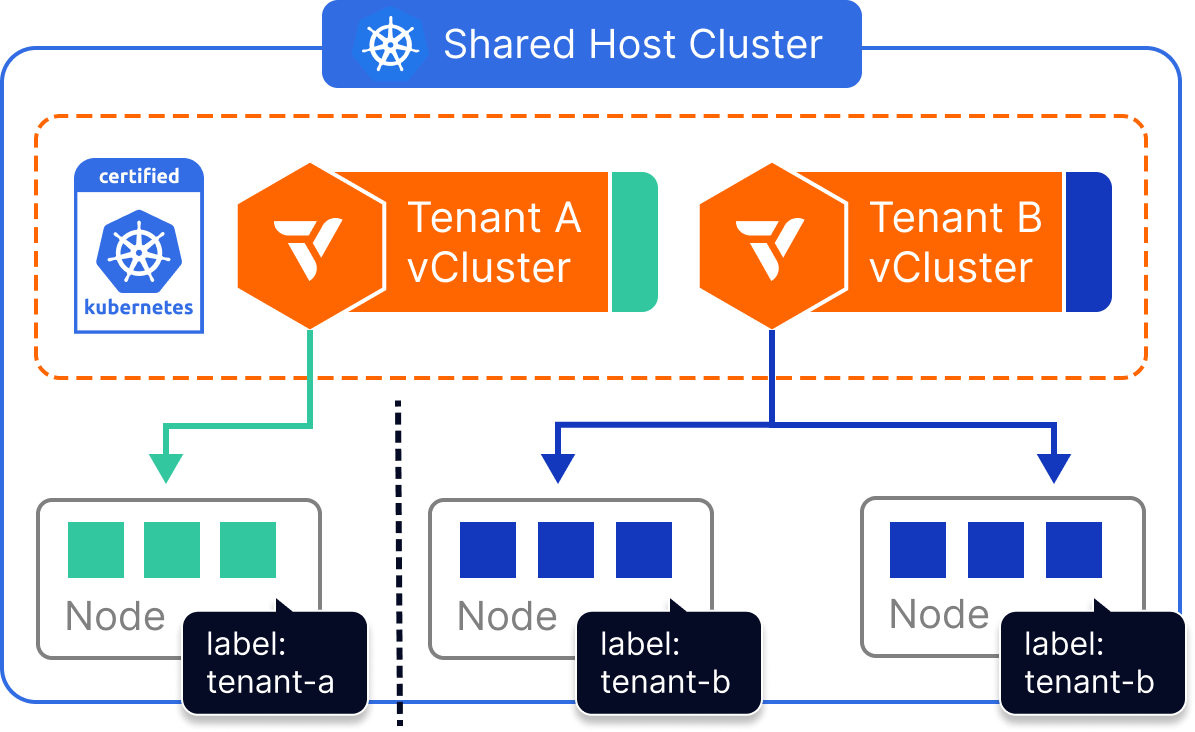
Dedicated Nodes strike a balance between hard separation and infrastructure efficiency, but require thoughtful governance and policy design.
Provision Fully Isolated Clusters for Tenants — Separate CNI, CSI, and Compute
Delivers maximum tenant isolation with dedicated clusters, ideal for regulated or production-critical environments.
Private Nodes provide the strongest isolation among vCluster tenancy models. In this setup, each virtual cluster runs inside its own dedicated Kubernetes host cluster—backed by physically separate nodes, a separate control plane, and separate infrastructure components like CNI and CSI drivers. From the tenant’s perspective, the environment behaves like a single-tenant Kubernetes cluster, with all platform services fully isolated.
This approach ensures that no tenant shares compute, networking, or storage with others. It’s best suited for highly sensitive workloads that require strict compliance, regulatory boundaries, or strong guarantees around performance, network isolation, and tenant autonomy.
Each vCluster is deployed into its own Kubernetes host cluster, provisioned with a dedicated set of physical nodes. The CNI, CSI, kube-proxy, and all other Kubernetes components are fully isolated per tenant.
Because vCluster runs on top of this separate host cluster, it inherits the benefits of virtual cluster abstraction (faster startup, CRD freedom, sleep mode, etc.), but adds an additional hard isolation boundary beneath it. Tenants cannot interfere with one another’s environments at any layer—from API server to node kernel.
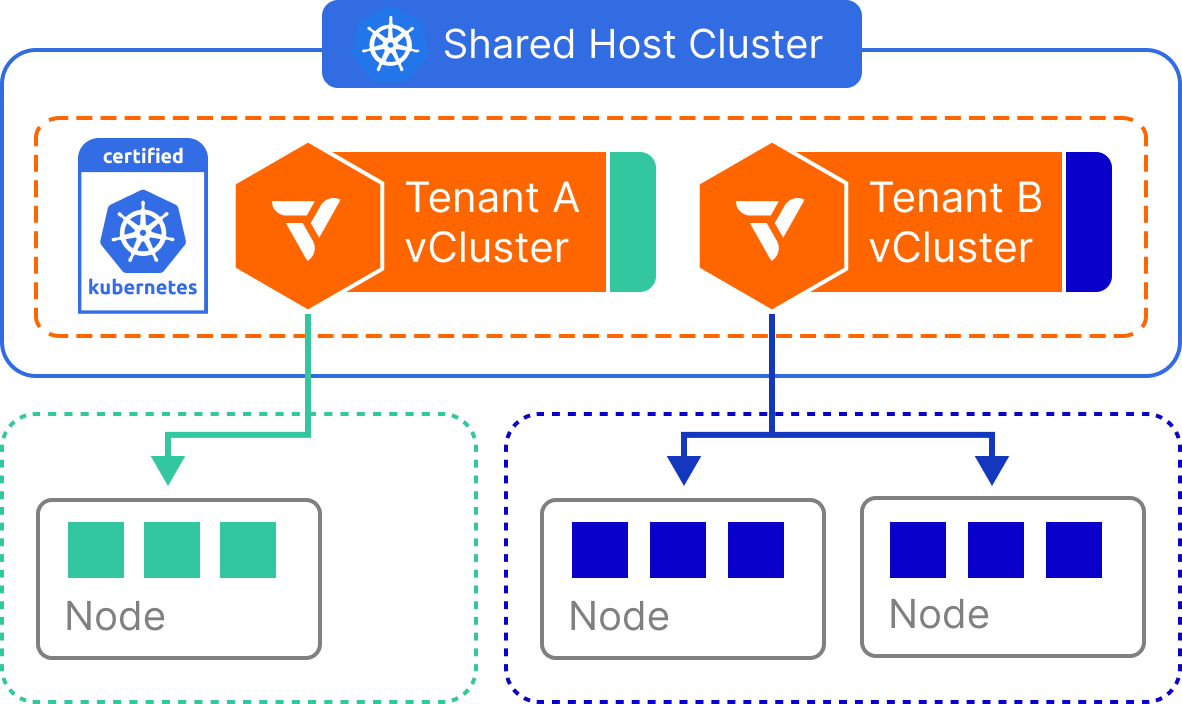
This model is ideal when tenant safety and independence are more important than resource efficiency.
Dynamic Node Autoscaling, Anywhere You Run Kubernetes
Unlock cloud-style elasticity across virtual clusters in public cloud, private cloud, and bare metal with embedded Karpenter.
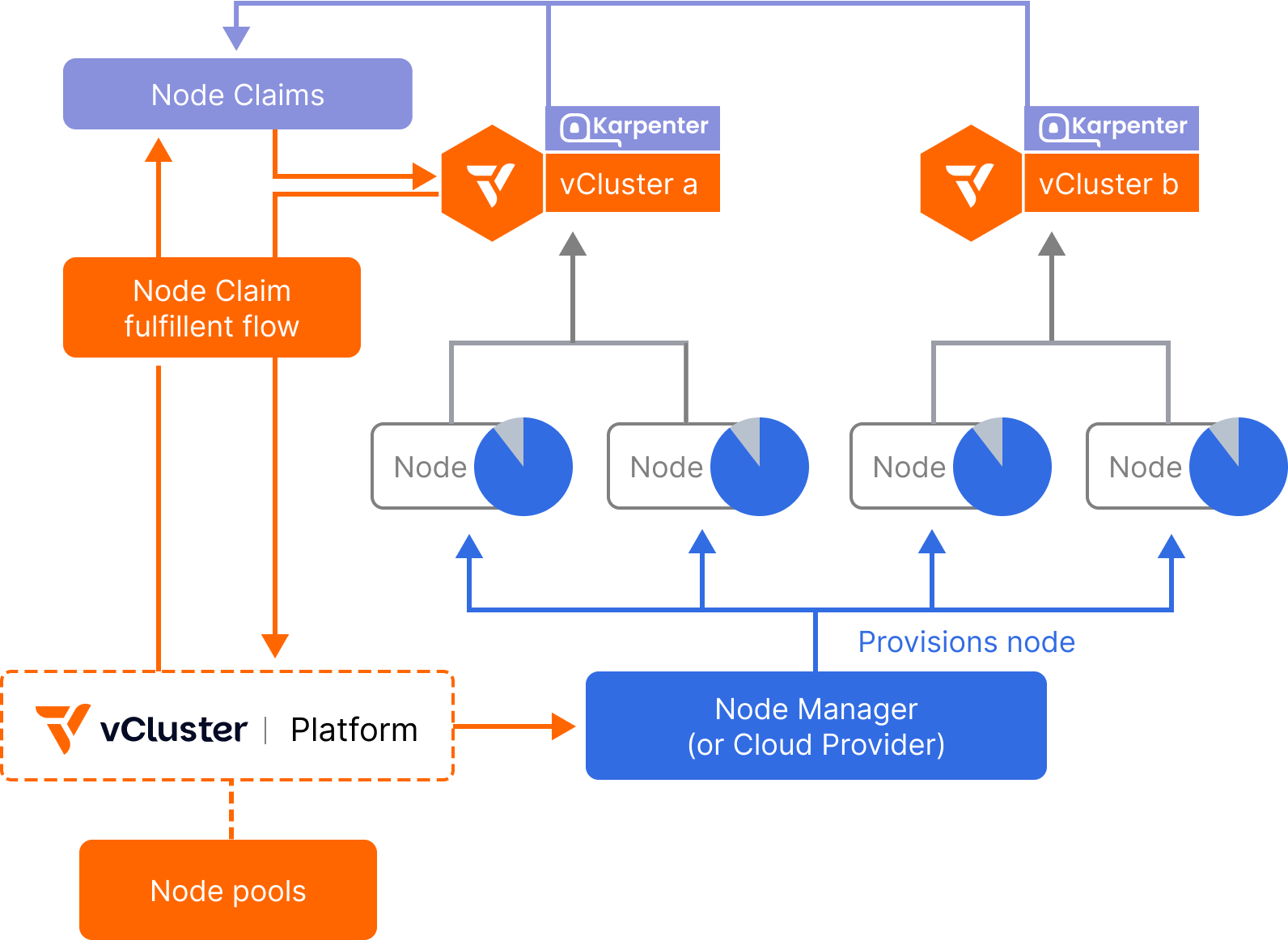
Auto Nodes integrates a managed instance of Karpenter directly inside each virtual cluster, transforming it into a fully isolated autoscaling unit. With dynamic provisioning and deprovisioning of compute across hybrid, multi-cloud, and even bare metal environments, platform teams can now scale workloads elastically, without over-provisioning or vendor lock-in.
Each virtual cluster can trigger the creation of NodeClaims, which the platform fulfills by dynamically scaling up the appropriate node pool, whether that means launching traditional cloud VMs, bare metal PXE-booted nodes, or virtualized environments like vNode or KubeVirt. Underutilized nodes are automatically drained and returned to the shared pool, improving efficiency and reducing cloud spend.
The vCluster Platform runs an embedded, fully configurable instance of Karpenter that listens to scheduling pressure and provisioning needs from all connected virtual clusters. When a virtual cluster’s scheduler detects the need for more compute (e.g., due to a pending pod), it submits a NodeClaim to the platform.
The platform’s Node Manager fulfills these claims by selecting from available Node Pools, each defined by a set of instance types, node classes, or backing infrastructure (e.g., GPU, ARM, x86, bare metal). Nodes are joined dynamically to the host cluster and assigned to the requesting vCluster.
Once the workload completes or scales down, unused nodes can be automatically removed, rebalanced, or reused by other virtual clusters.
Despite these, the payoff is massive in terms of scalability, efficiency, and automation.
Run Virtual Clusters Without a Host — vCluster Standalone for Maximum Portability
Spin up lightweight virtual clusters anywhere, without relying on a Kubernetes host cluster.
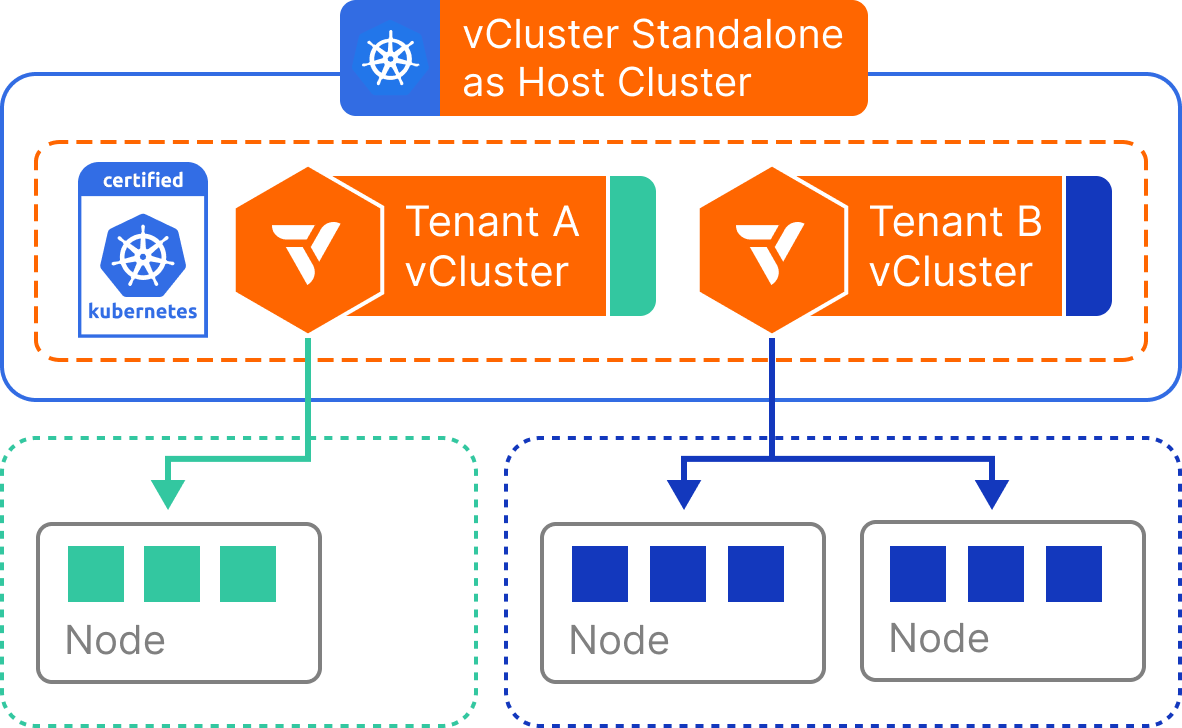
Standalone vClusters eliminate the need for a pre-existing Kubernetes host cluster. Instead, the virtual cluster runs as a fully self-contained process—typically inside a single container or VM—capable of bootstrapping its own control plane and simulating the Kubernetes environment.
This model is ideal for use cases where speed, portability, or independence are paramount. Whether you’re running workloads in CI pipelines, demos, local development setups, or air-gapped environments, Standalone vCluster offers a fast, lightweight way to provision isolated Kubernetes environments without relying on cluster-level infrastructure or orchestration.
A Standalone vCluster launches its own lightweight control plane components (like a virtual API server and virtual scheduler) and backs workloads with a local Kubernetes-compatible runtime. Since no Kubernetes host cluster is required, virtual clusters can run independently in a container, virtual machine, or even on a developer laptop.
Despite being self-contained, a Standalone vCluster behaves just like a regular Kubernetes control plane: it supports custom resources, RBAC, workload scheduling, and even integrations with CI/CD tools. Workloads are managed entirely within the virtual cluster and do not require a physical cluster node pool to function.
vCluster Standalone is powerful for portability, but isn't a replacement for full-scale multi-tenant infrastructure.
Provision a Cluster Per Tenant — Strong Isolation, Heavy Overhead
The traditional method for tenant separation. Offers full control and security at the cost of complexity, duplication, and scalability challenges.
Provisioning a fully separate Kubernetes cluster for each tenant is the most well-understood and straightforward form of multi-tenancy. Every tenant gets their own physical or virtual cluster—including a dedicated control plane, node pool, and platform services like CNI, CSI, monitoring, and logging.
While this model offers the strongest isolation guarantees, it comes with substantial operational and financial cost. It often leads to cluster sprawl, duplicated effort across environments, and growing platform complexity as the number of tenants increases.
This approach remains common in regulated industries and traditional enterprise settings, but it is increasingly being replaced by more scalable, efficient alternatives, like vCluster.
Each tenant receives its own Kubernetes cluster, either provisioned manually or via infrastructure-as-code tools (e.g., Terraform, Cluster API, cloud-native APIs). All cluster resources are isolated by design: tenants cannot interact with each other, and workloads are scheduled to entirely separate compute environments.
This isolation extends beyond compute—each tenant also gets independent CRDs, webhooks, admission controllers, and control plane components. But because every cluster runs the full stack of infrastructure services, the cost and complexity increase linearly with the number of tenants.
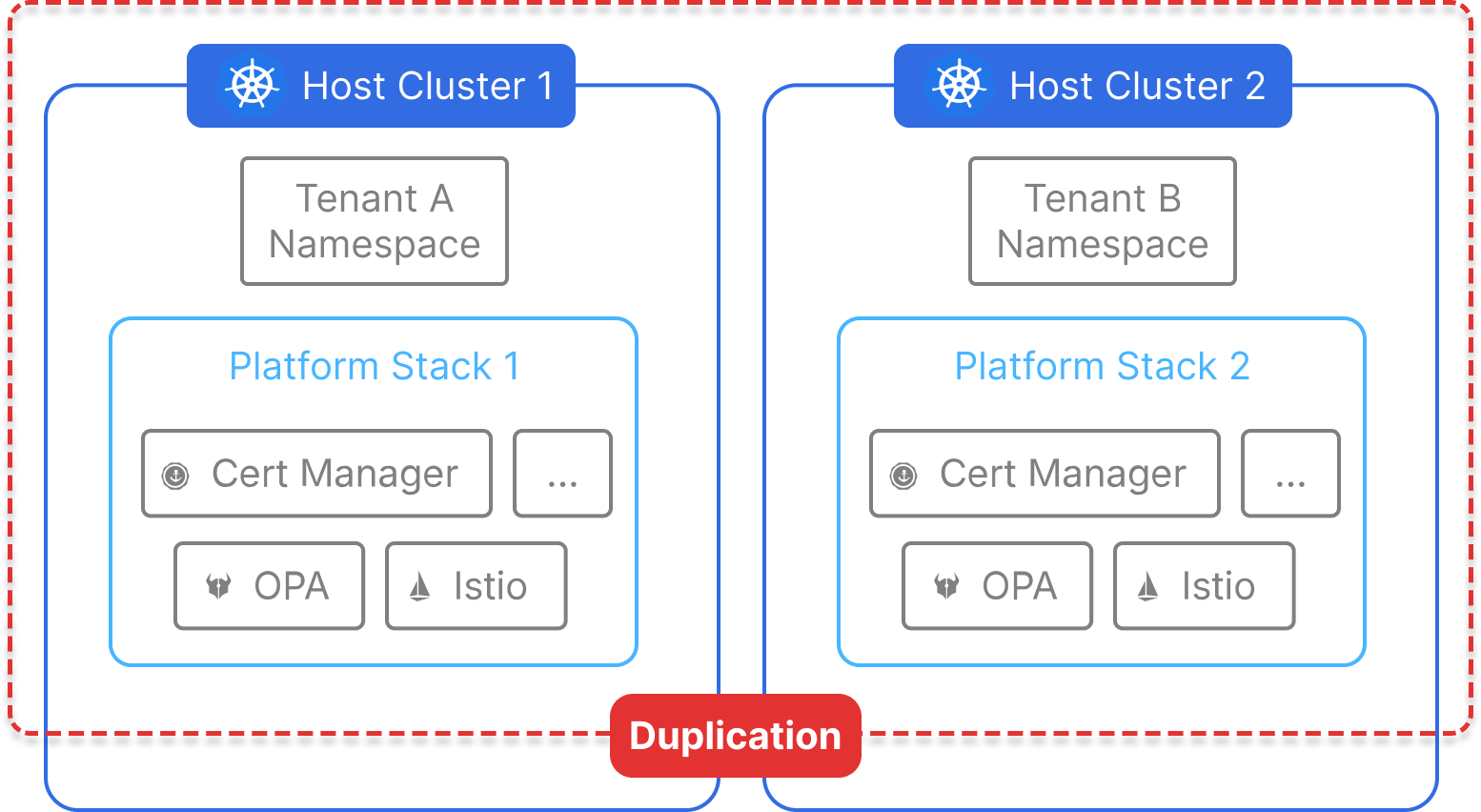
While this model works for high-security workloads, most teams can achieve similar benefits with less cost and complexity using vCluster.
There’s no one-size-fits-all model for Kubernetes multi-tenancy—but with vCluster, you don’t have to choose just one. You can combine tenancy models to suit different environments, teams, or workloads, and evolve your architecture over time.
Start with Namespace Syncing or Shared Nodes. Grow into Dedicated or Private Nodes. Leverage Auto Nodes to keep infrastructure efficient at every step.
And when you’re ready to abstract away the Kubernetes learning curve entirely, vCluster gives you the tools to create a seamless internal platform with fast, secure, tenant-aware virtual clusters at its core.
Ready to see it in action? Try vCluster today →
Deploy your first virtual cluster today.
