AI Cloud Providers · ClusterMAX™ Criteria Guide
The Platform Layer That Upgrades Your ClusterMAX™ Score
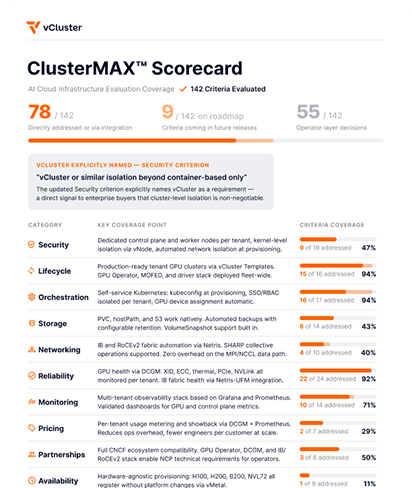
ClusterMAX™ evaluates AI cloud providers across 10 dimensions. This guide maps each criterion to the specific capabilities in vCluster, vNode, and vMetal that help you improve in that area, including the Security criterion that now explicitly names vCluster as a requirement.