Kubernetes 1.36: User Namespaces Are Finally GA – And Why It Matters for Tenant Isolation

May 27, 2026
|
19
min Read

After ten years of KEPs, six years of active development, and four releases of beta polishing, User Namespaces in Kubernetes graduated to General Availability in v1.36 (released April 23, 2026).
If you only read one thing from the release blog, read this:
A process running as root inside a container is also seen from the kernel as root on the host. If an attacker manages to break out of the container, whether through a kernel vulnerability or a misconfigured mount, they are root on the host.
That single sentence has been the defining limitation of "containers as a security boundary" since the day Docker shipped. v1.36 is the day Kubernetes finally has a clean, in-tree, default-on answer to it.
This post is the deep dive: what user namespaces actually do, the kernel breakthrough that made them practical for stateful pods, the exact YAML to enable them, the CVEs they neutralize, the limitations the release blog politely glosses over, and where they fit alongside node-level isolation tools like vNode for production tenant isolation.
For years the recommended container security mantra has been: "don't run as root." Pod Security Standards enforce it, OPA gatekeeper rules enforce it, every CIS benchmark enforces it.
There is a real problem with that advice: a huge fraction of real workloads need root inside the container. Database servers binding privileged ports, build tools doing chroots, network functions calling iptables, sidecars mounting filesystems, anything doing Docker-in-Docker, anything that does apt-get install. Telling those workloads "just run as 1000" means rebuilding the image, hacking the entrypoint, or giving up the feature.
So operators routinely cave and grant root. And the second they do, the kernel sees the same thing it has always seen: UID 0 in the container is UID 0 on the host. A container escape – runc CVE, kernel LPE, badly-mounted hostPath, leaked socket – and the attacker is running as the host's actual root, with full power over every other pod on the node, the kubelet, the container runtime, and any mounted secrets.
Capabilities, seccomp, AppArmor, and SELinux all reduce the blast radius. None of them change the underlying truth: the process identity is still root.
User namespaces fix that at the kernel level.

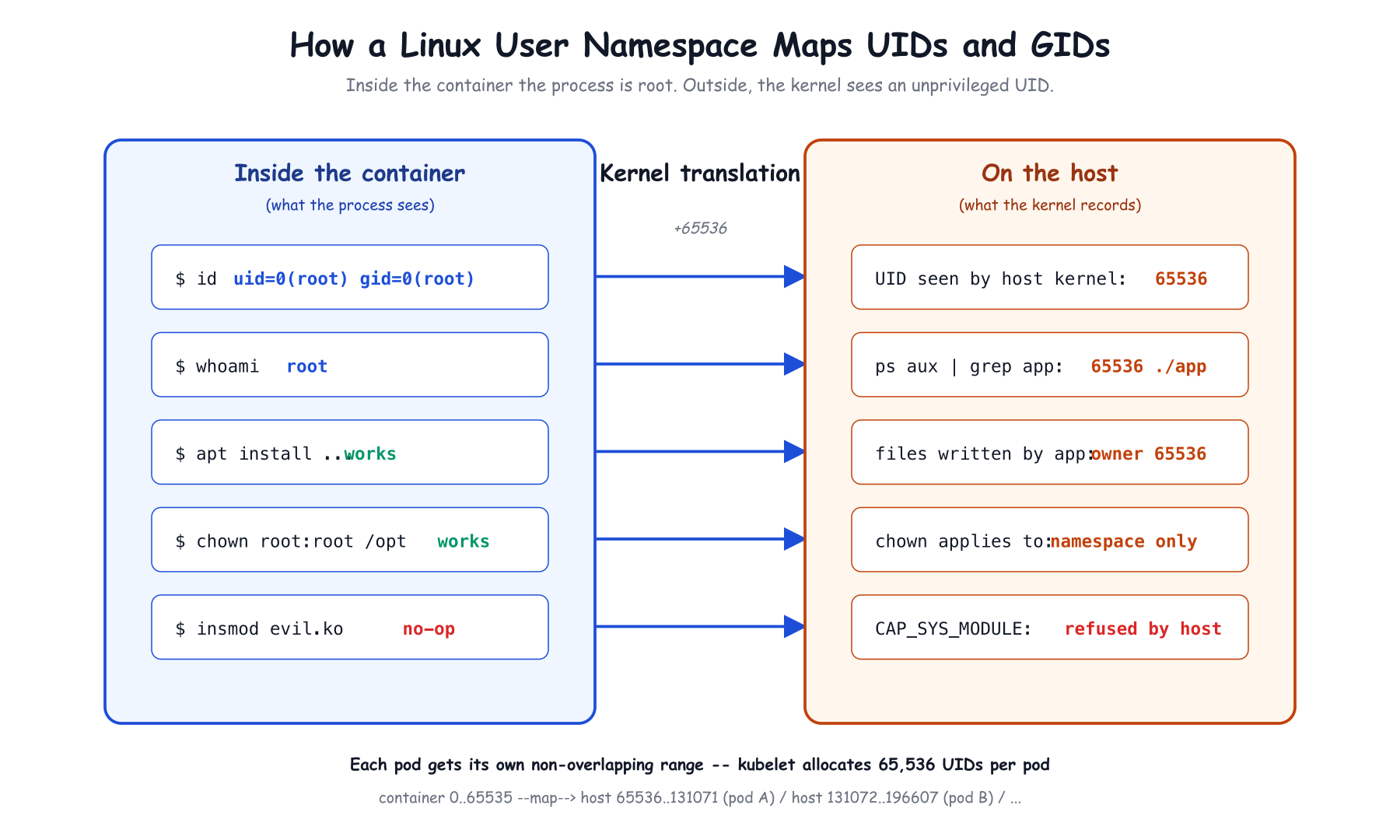
A Linux user namespace is a kernel feature (stable since 3.8) that gives a process its own private mapping of UIDs and GIDs. Inside the namespace, the process can see itself as UID 0 (root). Outside the namespace – to the host kernel, to ps aux, to file ownership on disk – it is some unprivileged UID like 100000.
The mapping is configured per-namespace and looks like this:
Inside container UID → Host UID
0 → 100000
1 → 100001
...
65535 → 165535
The process inside truly believes it is root. It can chown files (within its namespace), chmod 4755 binaries, install packages, run iptables against its own network namespace. None of that grants it any privilege over the host. If a kernel bug lets it escape to the host process tree, it lands as UID 100000 – a user that owns nothing, can read nothing sensitive, and can kill no other process.
Capabilities behave the same way: with hostUsers: false, CAP_SYS_ADMIN is administrative only over the namespace's own resources. CAP_SYS_MODULE is literally void – the kernel will not let a namespaced root load a kernel module no matter what the pod spec requests.
This is the property the Kubernetes blog refers to as "namespaced capabilities," and it is the reason user namespaces are different in kind from runAsUser: 1000. You do not have to rewrite the workload. The workload runs as root. The host just refuses to believe it.
User namespaces have existed in Linux for over a decade. Container runtimes have used them for years (rootless Podman, rootless Docker, LXC). So why did Kubernetes take six years?
Volumes.
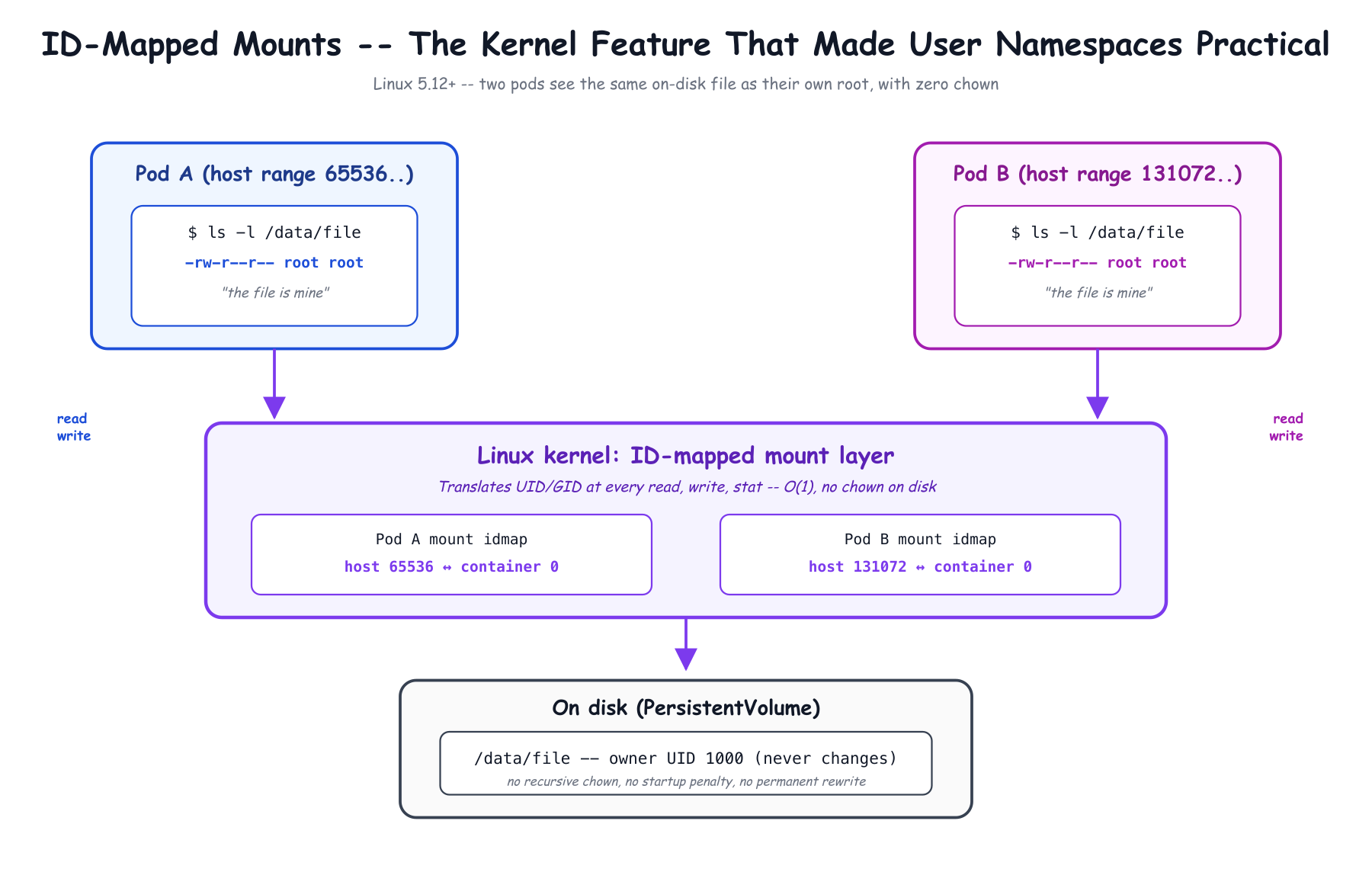
Imagine pod A is mapped to host UID range 100000–165535 and pod B is mapped to 200000–265535. Both containers want to read a file from a PersistentVolume. On disk, that file is owned by some real UID. For pod A's "root" to read it, the file must be owned by 100000. For pod B's "root" to read the same volume, it must be owned by 200000. You cannot have both.
The early implementations solved this by chown'ing every file in the volume on pod startup to match the pod's host UID range. For an emptyDir this is fine. For a 50TB persistent volume with a few million inodes, it is a multi-minute startup penalty – and worse, it permanently rewrites file ownership, breaking any other pod that wants to mount the same volume with a different UID range.
The fix is a kernel feature called ID-mapped mounts, introduced in Linux 5.12 and refined through 6.3. The mount itself carries a UID translation table. The kernel applies it transparently at every read, write, stat, and chown:
This is the breakthrough. Without idmap mounts, Kubernetes user namespaces would have shipped years ago and been useless for any pod with persistent state. With them, you can flip hostUsers: false on a StatefulSet running Postgres tomorrow and not pay any startup penalty at all.
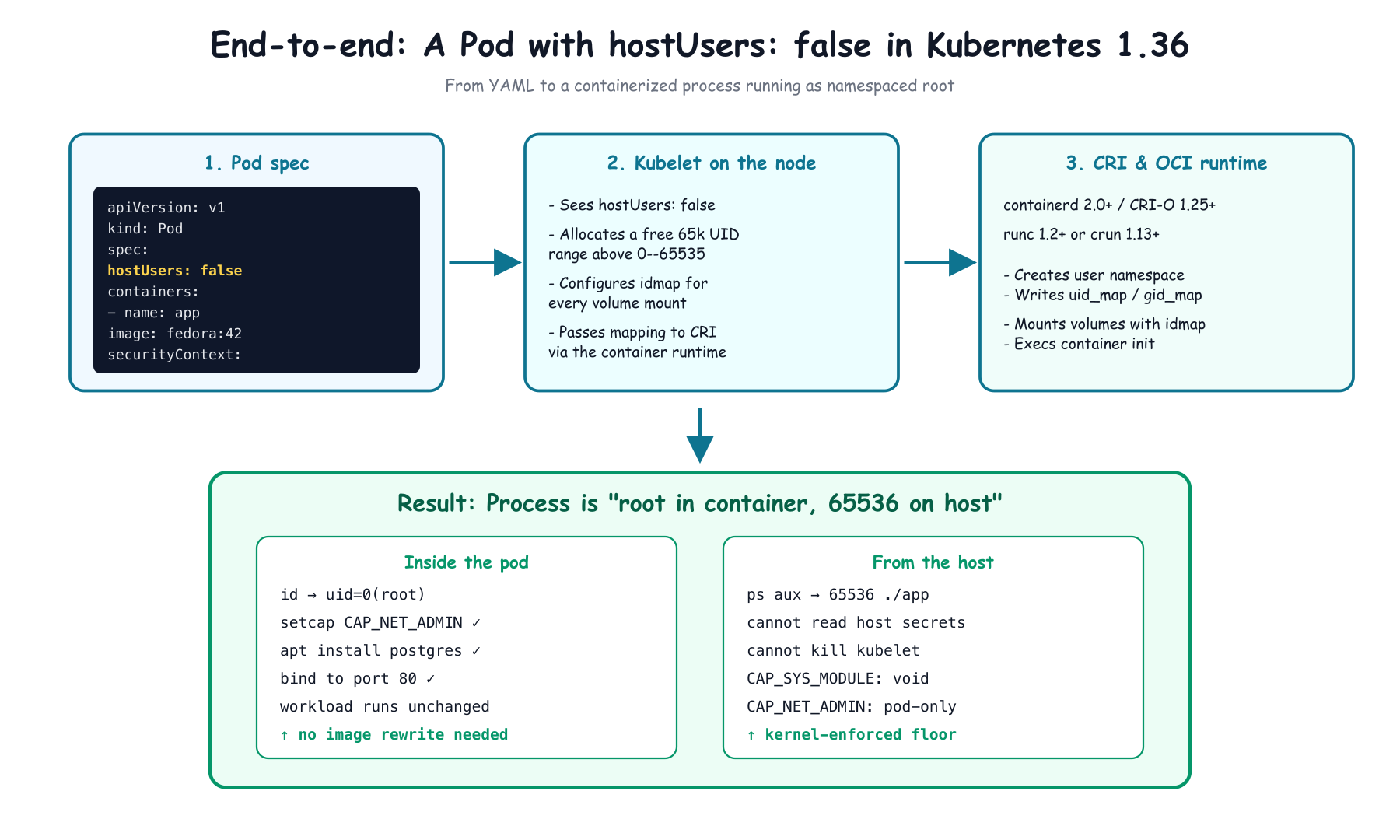
Here is the entire opt-in:
apiVersion: v1
kind: Pod
metadata:
name: privileged-but-contained
spec:
hostUsers: false # the whole feature
containers:
- name: app
image: fedora:42
securityContext:
runAsUser: 0 # root inside the container
capabilities:
add: ["NET_ADMIN"] # namespaced, harmless on the host
A few things worth knowing about that spec:
By default the kubelet allocates each pod 65,536 contiguous UIDs/GIDs from a range above 0–65535, guaranteeing no two pods on a node share a mapping. If you want a custom range, you create a system user named exactly kubelet on the node, install getsubids (from shadow-utils), and add entries to /etc/subuid and /etc/subgid.
User namespaces neutralize a specific class of attack: anything that depends on the container's UID being equal to a host UID with privilege. Some real examples:
| CVE / Issue | Class | Without hostUsers: false | With hostUsers: false |
|---|---|---|---|
| CVE-2019-5736 (runc host binary overwrite) | Container escape | Attacker overwrites /usr/bin/runc on host as root | Attacker is unprivileged on host, write fails |
| CVE-2021-25741 (subPath symlink race) | Host file read | Pod reads arbitrary host files matching pod's UID | Pod's UID does not match any sensitive host UID |
| CVE-2022-0492 (cgroup release_agent) | Privilege escalation via cgroups | CAP_SYS_ADMIN in pod can write release_agent | CAP_SYS_ADMIN is namespace-scoped, write fails |
| CVE-2024-21626 (runc fd leak) | Container escape | Process inherits host fd as root | Process inherits fd as unprivileged user |
| Generic kernel LPE during escape | Defense in depth | Lands as host root | Lands as unprivileged host user |
This is not a theoretical list. These are HIGH-severity CVEs that have shipped in the last few years. User namespaces would have neutered or significantly defanged every one of them.
The Kubernetes release blog is honest about this:
This feature also enables a critical pattern: running workloads with privileges and still being confined in the user namespace. When hostUsers: false is set, capabilities like CAP_NET_ADMIN become namespaced ... This effectively enables new use cases that were not possible before without running a fully privileged container.
Translation: workloads that previously required a privileged pod – and therefore required you to trust them at host-root level – can now run with their privileges scoped to the pod. That is a category change.
GA does not mean "every cluster gets this for free." Here is the requirements list, and it is not trivial:
| Component | Minimum version | Notes |
|---|---|---|
| Linux kernel | 6.3+ | Earlier 5.12+ kernels work for some volume types but tmpfs (used by service account tokens, Secrets) needs 6.3 |
| Filesystem at /var/lib/kubelet/pods/ and all pod volumes | idmap-capable | btrfs, ext4, xfs, fat, tmpfs, overlayfs are supported |
| containerd | 2.0+ | |
| CRI-O | 1.25+ | |
| OCI runtime | runc 1.2+ or crun 1.13+ | |
| cri-dockerd | not yet supported | Mirantis/cri-dockerd#74 |
A few realities that flow from this list:
This is still a giant step forward. It is not a magic flag.
User namespaces solve the process identity problem for a running container. They do not solve everything.
Two specific gaps matter for tenant isolation:
The first gap is the one most people miss. The second gap is the well-known one.
For the second gap, hypervisor-grade options exist (Kata, Firecracker, Edera) and userspace syscall sandboxes exist (gVisor). They each pay a real cost: VM boot time and memory tax for the hypervisor route, syscall-translation latency and compatibility loss for gVisor. They also each restrict what tenants can do – gVisor blocks privileged operations entirely; Kata loses things like kubectl port-forward because the kubelet's network namespace assumptions break across the VM boundary.
vNode lives in this exact landscape, and the comparison vCluster ships on its site puts it head-to-head with Kata, gVisor, and Sysbox – not as a different category, but as a peer alternative with a different mechanism. After digging into how it actually works, that positioning is defensible. Here is why.
The shorthand "vNode is user namespaces + seccomp" is incomplete. The official one-line framing from the vCluster team is more accurate: VM-grade isolation, container-grade performance, zero workload changes.
How that actually works is what makes the comparison defensible.
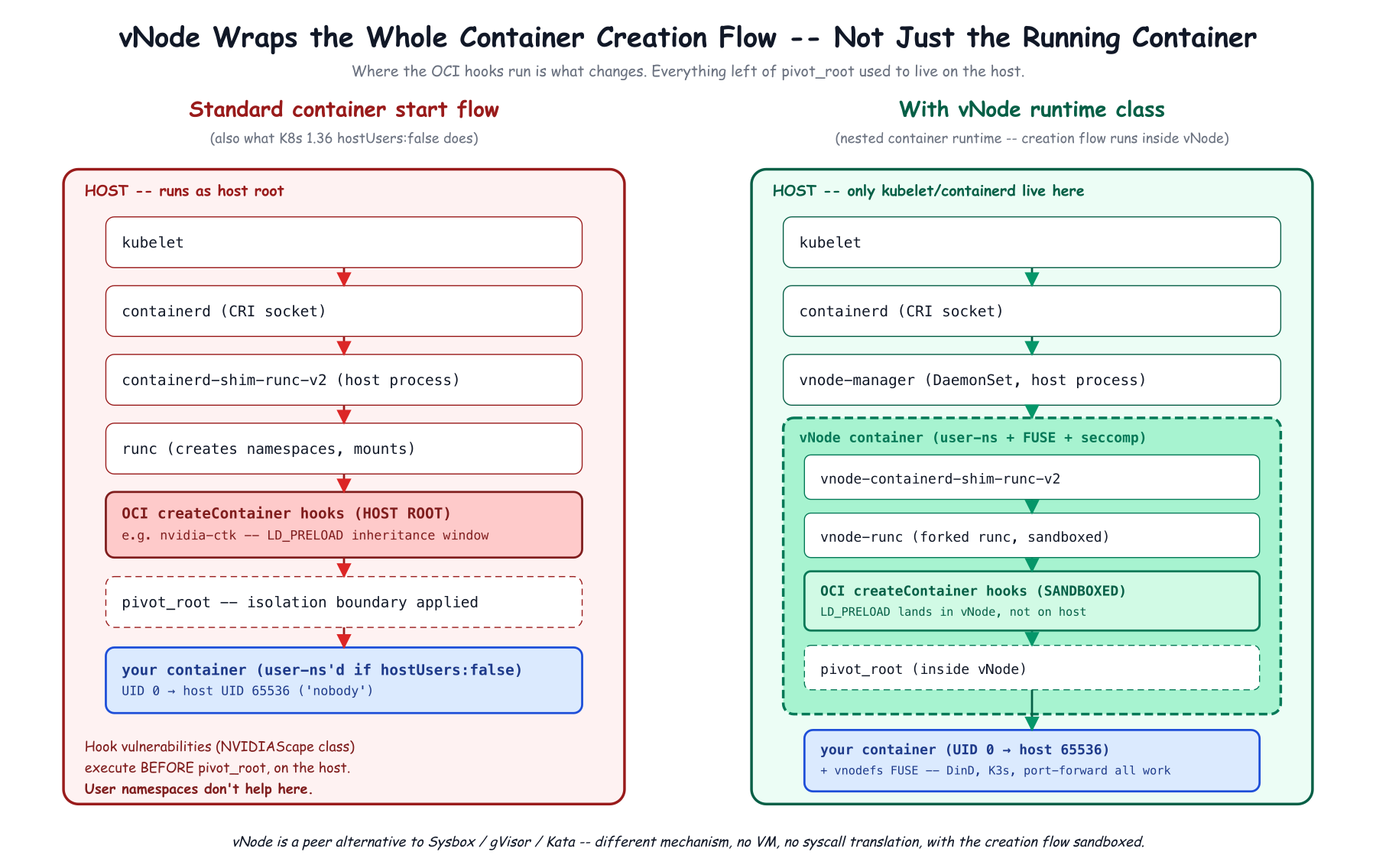
vNode is a nested container runtime. Not a sidecar, not a policy engine. Each tenant's workloads run inside an isolated vNode container that acts as a lightweight "mini-host" – the workload sees a normal Linux environment, the host kernel sees an unprivileged process. No hypervisor. No guest kernel.
The actual on-node components are:
In a standard Kubernetes setup, every step from the containerd shim through runc through OCI hooks executes on the host as host root, before pivot_root. With vNode, that whole chain (vnode-containerd-shim-runc-v2 → vnode-runc → OCI hooks → pivot_root → workload) runs inside the vNode container. Containers-in-containers, safely.
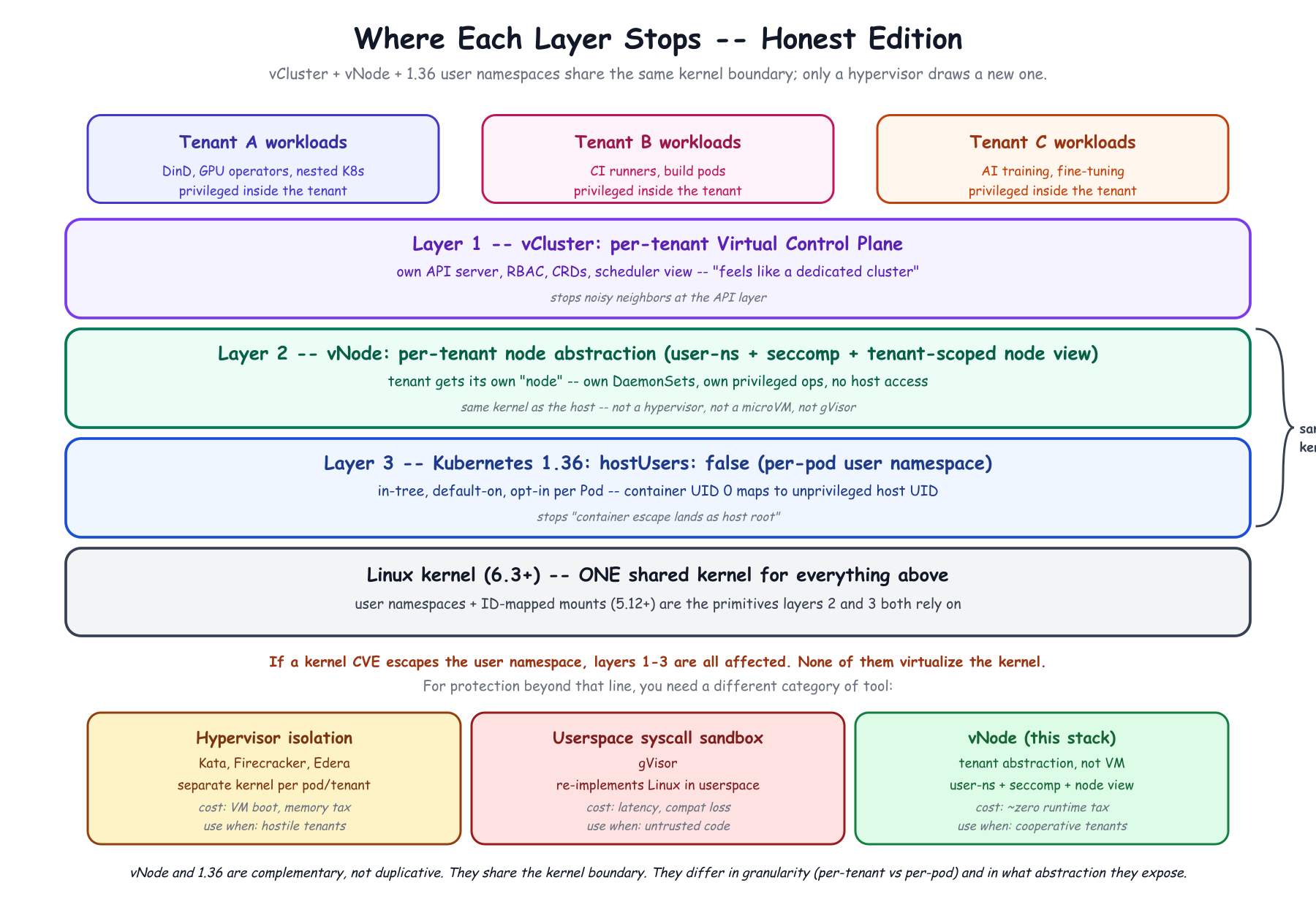
On top of that nesting, vNode applies a defined three-layer security model.
Every vNode is an unprivileged user on the host. Each gets a unique UID/GID range; container UID 0 maps to an unprivileged host UID at 65536+ ('nobody').
ID-mapped mounts (Linux 6.1+) handle the translation at zero cost: no recursive chown, no startup penalty. vNode's documentation lists support for ~50 filesystems including ext4, btrfs, xfs, and overlayfs.
The bottom line: even a full container escape lands the attacker on the host as nobody – unprivileged, with no access to other vNodes' files or processes.
Sensitive kernel interface subpaths in /proc and /sys are virtualized via a FUSE filesystem (vnodefs). The workload reads /proc/uptime and gets its own uptime. Writes to /proc/sys/... are scoped per-container. Host hardware identifiers in /sys/devices/virtual/dmi are completely hidden.
| Path | Mechanism | What the workload sees |
|---|---|---|
| /proc/uptime | FUSE (vnodefs) | Container's own uptime, not host's |
| /proc/sys/* | FUSE (vnodefs) | Per-container sysctls (hostname, pid_max, ip_forward, etc.) |
| /proc/[pid]/* | PID namespace | Only own processes visible |
| /sys/kernel | FUSE (vnodefs) | Kernel parameters hidden from workload |
| /sys/devices/virtual/dmi | FUSE (vnodefs) | Hardware identifiers completely hidden |
This is what lets Prometheus node-exporter, K3s, Docker-in-Docker, and GPU operators actually run inside the vNode – they expect a real node and vNode gives them one without exposing the underlying host.
vNode classifies syscalls into three buckets, surgically rather than wholesale:
This is the explicit philosophical contrast with gVisor:
| Aspect | gVisor | vNode |
|---|---|---|
| Syscall handling | Reimplements ~237 syscalls in userspace Sentry | Pass-through as unprivileged |
| Kernel attack surface | ~68 syscalls actually exposed | Full kernel, unprivileged user |
| /proc, /sys isolation | Reimplemented in Sentry | FUSE virtualization |
| Performance | 10–30% I/O overhead | Near-native |
| Compatibility | ~70% syscall coverage | Full Linux |
| Philosophy | Don't trust the kernel at all | Trust parts of the kernel, harden it, then isolate tenants |
gVisor's bet is "rewrite the entire kernel in userspace so the workload never reaches it." vNode's bet is "trust parts of the kernel, but make the process unprivileged and virtualize the things that leak host info." Both are defensible. They have very different cost profiles.
The vCluster team is explicit that vNode is additive to Kubernetes security, not a substitute. Kubernetes-imposed seccomp profiles, capability drops, and resource limits are preserved and passed through. vNode adds its layer on top:
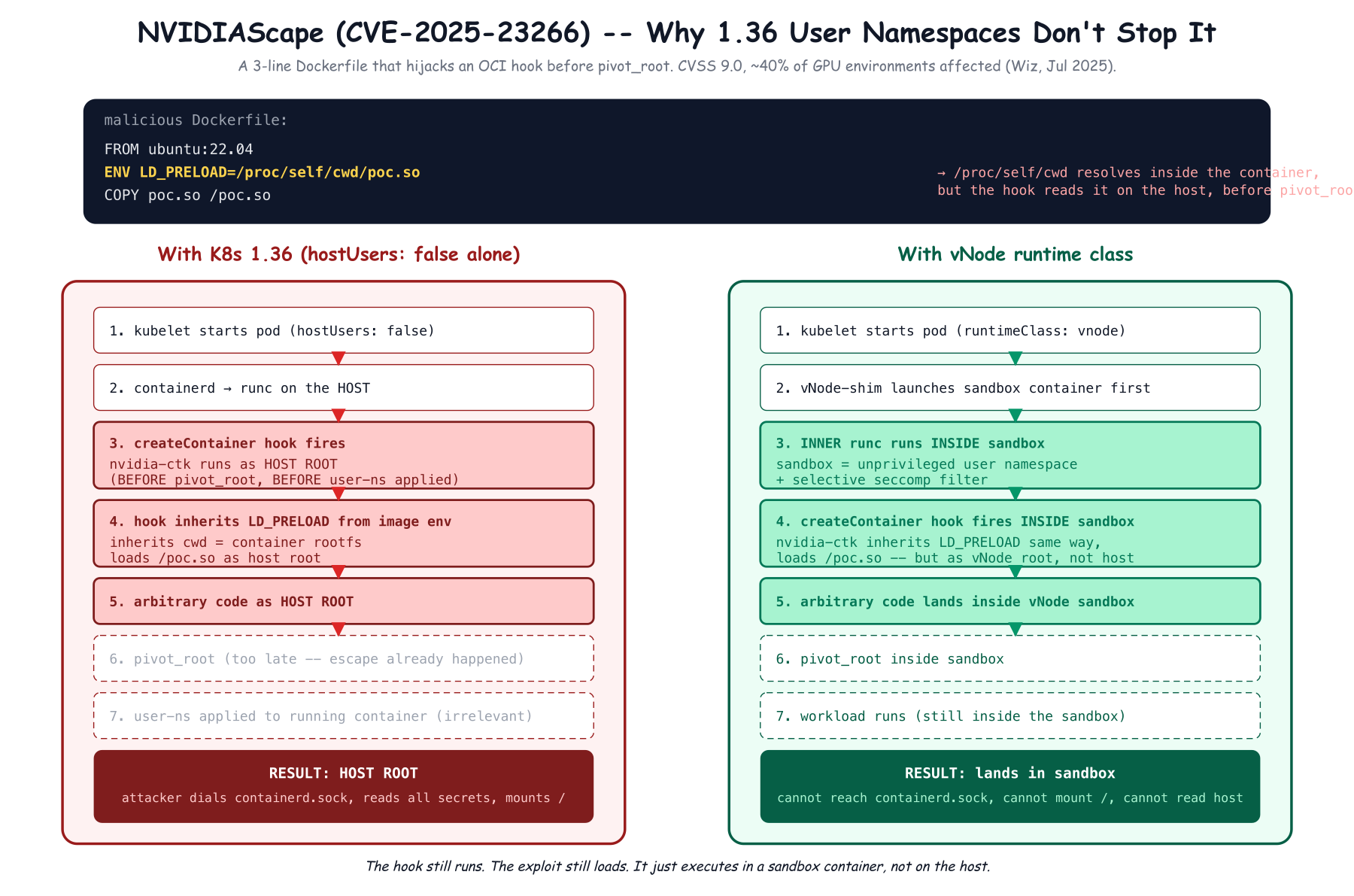
In July 2025, Wiz disclosed CVE-2025-23266 – "NVIDIAScape" – a CVSS 9.0 container escape in the NVIDIA Container Toolkit. Wiz estimated 40% of GPU-using environments were affected.
The exploit is, almost insultingly, three lines in a Dockerfile:
FROM ubuntu:22.04
ENV LD_PRELOAD=/proc/self/cwd/poc.so
COPY poc.so /poc.so
That's it. Once the malicious image is run on a node with a vulnerable NVIDIA Container Toolkit:
Game over. The attacker now has root on the host and can dial containerd.sock directly to start a fully-privileged hostPath container, mount the host filesystem, exfiltrate every secret on the node.
Now let's apply Kubernetes 1.36 user namespaces to this exact attack. Set hostUsers: false on the malicious pod. What changes?
Almost nothing. The user namespace is created for the eventual container process. The createContainer hook runs before the user namespace and pivot_root are applied – it runs as the host's runc, as host root, exactly as before. The malicious poc.so loads, executes as host root, and the breakout succeeds.
vCluster's own engineering blog states this explicitly:
"Unlike the seccomp filters gVisor applies or the recently introduced user namespaces feature in Kubernetes, we don't apply any security measures against a user-defined container [… instead vNode wraps the workload in a hardened sandbox container]. Even if container escape occurs, the attacker would just land in the virtual node which is our vNode sandbox container rather than the actual host."
This is the point I missed in the previous draft. K8s 1.36 user namespaces do not protect against the OCI-hook class of vulnerabilities. vNode does, by construction, because the hook executes inside the vNode sandbox. The attacker's LD_PRELOAD payload still loads – but it runs inside the vNode container, not on the host. Lands in the sandbox. Cannot reach /run/containerd/containerd.sock, cannot start a privileged hostPath pod, cannot mount the host filesystem.
This is not theoretical. NVIDIAScape was a real, exploited, 40% attack-surface CVE. The pattern – malicious OCI hook context inheritance – recurs whenever a runtime ships hooks. vNode mitigates an entire class of these by relocating the creation flow into a sandbox.
This mirrors vCluster's own published How vNode Compares chart, with one extra row I think readers need.
| Capability | vNode | K8s 1.36 hostUsers: false | Sysbox | gVisor | Kata Containers |
|---|---|---|---|---|---|
| Isolation approach | User namespaces + FUSE + targeted seccomp | User namespaces | User namespaces | Userspace syscall interception | Micro-VMs |
| Low overhead | Yes | Yes | Partial | No | No |
| Fast startup time | Yes | Yes | Yes | Yes | No |
| Low performance impact | Yes | Yes | Yes | Partial (10–30% I/O tax) | No |
| High tenant autonomy | Yes | No | Partial | No | Yes |
| High security strength | Yes | No | Partial | Yes | Yes |
| High networking & storage isolation | Yes | No | No | No | Yes |
| Protects against OCI-hook vulnerabilities (NVIDIAScape class) | Yes | No | No | No | Yes |
| Low failure blast radius | Yes | Partial | Yes | Partial | No |
| Compatibility with cloud providers | Yes | Yes | No | Partial | No |
| Kubernetes native | Yes | Yes | No | Yes | Yes |
| Ease of use | Yes | Partial | Partial | No | No |
| Commercial support & maintenance | Yes | No | No | No | No |
| Kernel-CVE cross-tenant protection | No (shared kernel) | No (shared kernel) | No | Yes (most syscalls never reach kernel) | Yes (separate kernel per pod) |
| Threat model fit | Cooperative multi-tenant platforms | Single-pod hardening | Docker-in-Docker focus | Untrusted code execution | Adversarial multi-tenant |
Two rows worth being literal about, because they often get muddied:
OCI-hook protection – vNode's nested-runtime architecture means OCI hooks (like nvidia-ctk's createContainer hook) execute inside the vNode container. The K8s 1.36 user-ns feature applies to the eventual container process, not the runtime that builds it. NVIDIAScape exploits this gap. vNode and Kata close it; raw user namespaces, gVisor, and Sysbox do not.
Kernel-CVE cross-tenant protection – vNode shares the host kernel. So does upstream Kubernetes user namespaces (hostUsers: false) and Sysbox. A kernel CVE that escapes a user namespace affects every tenant on the node for all three. Kata gives a separate kernel per pod; gVisor implements most syscalls in userspace so they never reach the host kernel. If your threat model is "regulated, adversarial multi-tenant environments where a kernel CVE between tenants is a compliance non-starter," you want a hypervisor option. For cooperative-tenant platforms – internal teams, CI runners, AI Cloud GPU customers, training pipelines – the OCI-hook protection and workload compatibility matter more, and vNode wins on the dimensions that actually constrain the design.
Short version: yes – and stronger than I initially thought.
I'll separate the answer into the two real questions.
Question 1: Is vNode still needed if I only run a few privileged pods on an otherwise single-tenant cluster?
Probably not. Set hostUsers: false and call it done. v1.36 is genuinely sufficient for hardening a privileged sidecar, a build pod, or a network-admin DaemonSet on a cluster where you trust everyone running pods.
Question 2: Is vNode still needed for multi-tenant platforms?
Yes, for three reasons that v1.36 does not address:
Where vNode is genuinely the right answer:
The pattern most platform teams actually land on:
vCluster for control plane Tenant Isolation. vNode for node-level Tenant Isolation – including OCI-hook protection and workload compatibility. v1.36 hostUsers: false as the per-pod kernel-level UID floor underneath both.
The three layers are independent and they compound. v1.36 strengthens the floor. vNode is what most multi-tenant platforms still need to build on top of that floor.
The three things worth doing this week:
Deploy your first virtual cluster today.
