Guide
How Neoclouds Can Launch a Managed Kubernetes Platform on Bare Metal in 2 Weeks
From GPU hardware to production-ready Kubernetes offering, skip the 12-month build cycle and go live in weeks, not quarters.
Picture a launch countdown in a noisy data center. With every beep, a new GPU generation arrives, and the one you just bought starts losing its shine. For neocloud providers, this is the core pressure: demand for AI compute is surging, but the window to monetize each hardware cycle is shrinking. Every month spent building internal platform foundations is a month of underutilized inventory and missed customers, while faster competitors turn the same silicon into revenue.
Meanwhile, the market has stopped buying “hardware access.” Customers expect a managed Kubernetes experience on day one: secure login, clean multi tenancy, predictable upgrades, real observability, and GPU scheduling that is consistent and measurable. If any of that feels manual, fragile, or unclear, trust collapses quickly and production workloads never land.
This creates a hard tradeoff. Do you optimize the newest GPUs, or do you spend quarters rebuilding Kubernetes reliability, isolation, and operations from scratch? The winning move is to decouple those concerns. With vCluster, providers can ship a credible managed Kubernetes offering in weeks by giving each tenant an isolated control plane on shared infrastructure, with safer upgrades and operational guardrails built in. That compresses time to market, improves GPU utilization, and frees teams to differentiate on performance, pricing, and customer experience.
Neocloud providers are entering the market at a moment of unprecedented opportunity and pressure. Demand for AI and GPU-backed workloads is accelerating, while new GPU generations are arriving faster than traditional infrastructure teams can adapt. Hardware also becomes outdated faster than ever. As a result, maximizing return on investment for a neocloud now depends primarily on how quickly more advanced GPU architecture can be made available to customers. Every month of delay directly erodes infrastructure value.
At the same time, customer expectations have shifted. Providers are expected to offer a fully managed Kubernetes experience from day one, including strong isolation, enterprise-grade reliability, and alignment with frameworks such as the ClusterMax, which increasingly act as a credibility benchmark. Without a solid managed Kubernetes offering, many providers remain stuck at bronze-level maturity and struggle to attract serious production workloads.
For most neoclouds, doing both is hard. Most providers spend a lot of time figuring out the provisioning piece rather than focusing on the customer experience and workload readiness that actually drive adoption. The default is to have high-end hardware and a not-so-efficient experience with manual steps.
So the question arises: Do you focus on optimizing the new GPUs or on delivering a better customer experience with a Kubernetes offering?
Providing an experience is essential. However, our research while working with different neoclouds shows that time-to-market has become a decisive competitive factor. Investing months in building an internal platform for a better experience means delaying customer onboarding and diverting focus away from other business-critical areas required for growth. In a fast-moving GPU market, this is the time most providers cannot afford to lose.
Building a managed Kubernetes service comparable to EKS, AKS, or GKE is far more complex than deploying upstream Kubernetes. It requires deep expertise across highly available control planes, advanced networking and load balancing, persistent storage orchestration, security and isolation, upgrades, and day-two operations. All of this must work reliably at scale, often on bare metal and in GPU-heavy environments.
For most neocloud providers, the first major constraint is talent. Experienced Kubernetes platform engineers are rare, highly sought after, and expensive. A useful question to ask is simple: do you already have a team that has built a hyperscaler-grade managed Kubernetes service?
If the answer is no, the implications can’t be solved by just hiring. Hiring senior Kubernetes expertise typically takes four to six months, assuming suitable candidates can even be found. During that time, GPU hardware remains underutilized and market opportunities are lost.
Even with the right hires, first-generation managed Kubernetes platforms often suffer from common early mistakes. These include weak cluster isolation, brittle upgrade paths, networking designs that fail at scale, alongside operational models that do not support thousands of customer clusters. Also, there’s a lack of isolation, flexibility and resource optimization. These problems usually surface only after customers are onboarded, when fixing them becomes expensive and disruptive, considering whether you have enough talent to build and fix simultaneously.
A plug-in model for Kubernetes infrastructure provides a practical alternative. Plug-In operates by bringing your own hardware, optimizing it, and integrating it with a platform such as vCluster, enabling providers to rapidly create many isolated GPU-backed Kubernetes clusters on your infrastructure with a better user experience. This avoids the operational overhead and risk of running thousands of full Kubernetes clusters per tenant.
With this approach, providers can move from minimal Kubernetes expertise to a production-ready managed offering in as little as two weeks. This dramatically accelerates time-to-market, improves GPU utilization, and establishes a clear path toward enterprise readiness without requiring hyperscaler-level platform engineering teams.
With the plug-in model, in a two-week timeframe, Neocloud can have success in all these areas:
These overall can gain a faster path to launching a managed Kubernetes service, higher infrastructure efficiency, and a clear foundation for enterprise growth.
However, before we dive deeper, let’s understand what a Kubernetes offering should look like.
For a neocloud, “managed Kubernetes” is not judged by the marketing promise. It is judged by the first hour of hands-on use. Customers arrive with a mental model shaped by upstream Kubernetes plus years of managed-service norms. They expect the cluster to be usable immediately, safely, and predictably. Anything that feels improvised, undocumented, or manually brokered erodes trust fast.
With so many areas, focusing on the day-one baseline that serious customers assume is already solved is the primary area to focus on. For neoclouds, that can be divided into 5 categories:
Customers do not evaluate managed Kubernetes platforms based on features alone. They evaluate confidence. Confidence that access is secure, operations are predictable, isolation boundaries are explicit, observability is usable, and GPU workloads behave in ways that are both schedulable and measurable. For neocloud providers, this confidence is not a nice-to-have. It is the product.
This reality fundamentally changes the build versus partner decision.
Building a managed Kubernetes platform from scratch is often underestimated. Even with aggressive hiring, assembling a capable Kubernetes team typically takes around four months. Platform design and implementation extend that timeline to six or eight months. Operational readiness, upgrade safety, support processes, and pilot customers push the timeline closer to ten or twelve months. The first paying customer usually arrives around the one-year mark, assuming no major setbacks.
For neoclouds, this timeline introduces material cost and risk. Engineering burn accumulates long before revenue. Operational gaps surface only under real customer load. Design mistakes in access control, upgrade guarantees, isolation, or GPU scheduling become expensive to unwind. Most critically, early customers are asked to trust a platform that is still maturing, precisely when trust is hardest to earn.
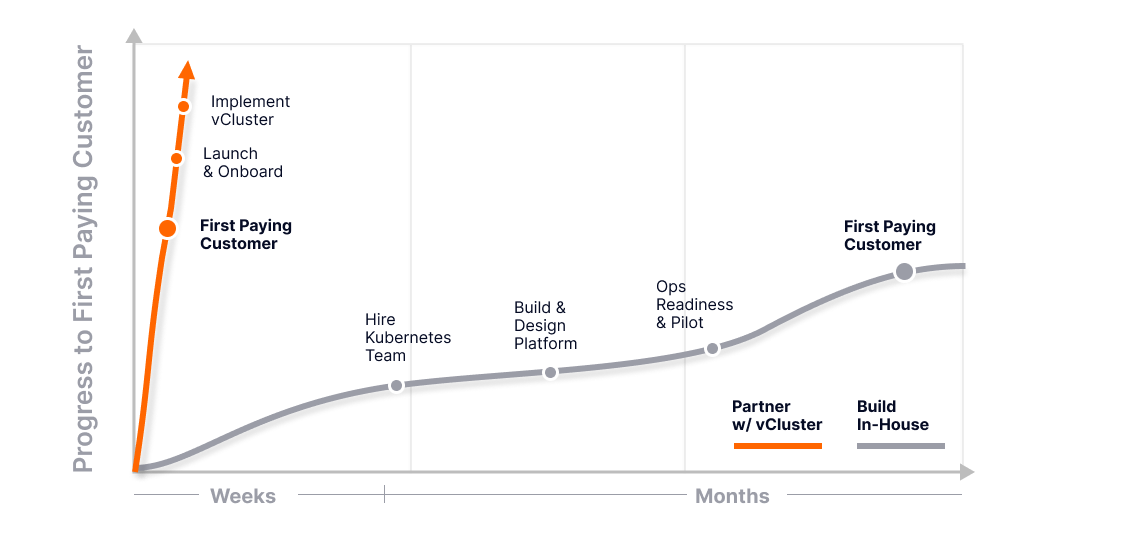
The hardest parts are not solved incrementally. Cluster access and identity, upgrade guarantees tied to operational SLAs, strong isolation boundaries, observability aligned with customer expectations, and GPU scheduling with performance guarantees all have to work together on day one. Partial solutions increase complexity without reducing risk. Each missing capability erodes customer confidence and delays commercial traction.
This is where partnering changes the equation.
Rather than spending eight to twelve months building foundational capabilities with uncertain outcomes, neoclouds can adopt a proven platform approach. vCluster provides a production-ready control plane abstraction that delivers secure access, explicit isolation, predictable operations, and measurable GPU behavior from the start. What typically takes quarters to design, implement, and harden can be operational in weeks.
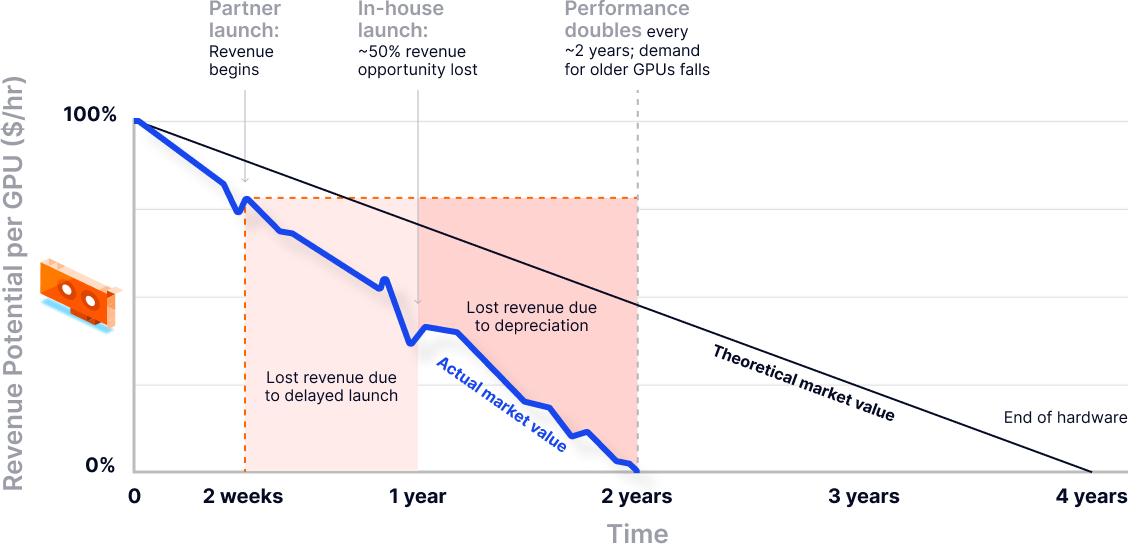
As you can see, factoring in GPU depreciation and performance impacts, this approach compresses time to market, reduces upfront engineering cost, and shifts risk away from core infrastructure. Teams can focus on differentiation, pricing models, and customer experience, while relying on vCluster to deliver the operational guarantees that customers evaluate first.
Let’s dive deeper into how the time to market equation changes with in-built vCluster capabilities.
The partner advantage is not about avoiding complexity. It is about choosing where to own it.
For neocloud providers, speed to market depends on delivering confidence, not rebuilding Kubernetes fundamentals. vCluster allows providers to focus engineering effort on differentiation, pricing, and customer experience, while relying on a proven control plane abstraction to deliver isolation, security, and operational guarantees from day one.
At the core of vCluster’s advantage is the separation of control planes at scale. Each tenant receives a fully isolated Kubernetes control plane with its own API server, lifecycle, and state, running on shared or dedicated (with private nodes) infrastructure. This model provides strong isolation and predictable behavior without the operational and cost overhead of managing a full cluster per tenant with SSO + RBAC alignment.
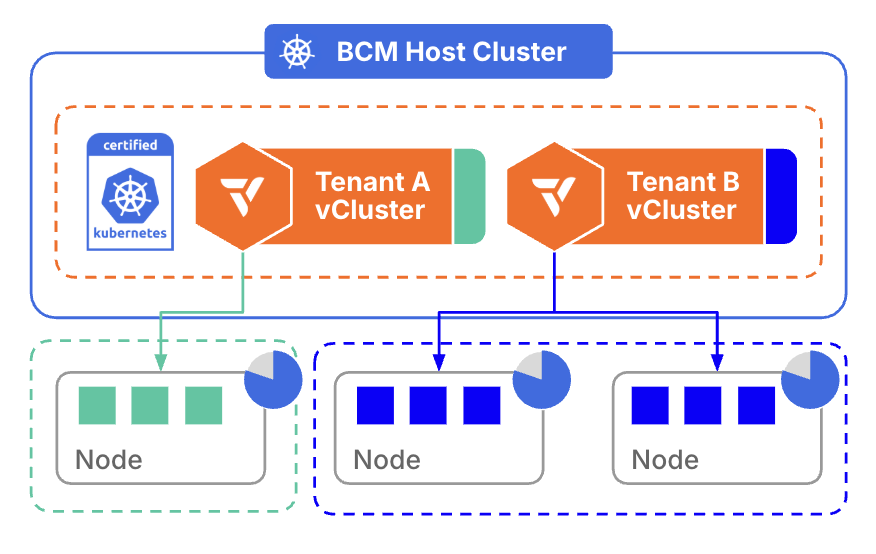
For neoclouds, this separation is not just architectural elegance. It is what enables confident multi-tenancy, safer operations, and scalable growth without exponential complexity.
vCluster dramatically reduces the time required to provision new tenant environments. Control planes can be created in minutes, without waiting for infrastructure bootstrapping, cluster creation workflows, or manual guardrails.
This speed directly impacts revenue. Faster provisioning shortens sales cycles, accelerates onboarding, and allows neoclouds to meet customer expectations for instant, self-service infrastructure without compromising isolation or control.
Traditional managed Kubernetes platforms couple tenant upgrades to infrastructure upgrades, creating high-risk, high-coordination events. vCluster decouples these concerns.
Tenants can be upgraded independently, tested in isolation, or rolled back without affecting others. Providers can introduce new Kubernetes versions, features, or policies incrementally. This reduces blast radius, lowers support burden, and enables realistic operational SLAs that customers can trust.
From a cost perspective, vCluster offers a structurally more efficient model than cluster-per-tenant approaches. Shared infrastructure reduces control plane overhead, minimizes idle capacity, and simplifies operations while preserving tenant isolation.
For neoclouds operating under margin pressure, this translates into lower cost per tenant and predictable scaling economics as customer adoption grows.
Operational maturity cannot be deferred. vCluster embeds resilience into day-one operations through snapshot and restore capabilities, enabling fast recovery, cloning, and migration of tenant control planes. Automated etcd healing and upgrades eliminate common failure modes that otherwise require deep Kubernetes expertise and manual intervention.
These capabilities reduce operational risk early, when teams are small and customer trust is hardest to earn.
The vNode architecture further abstracts worker nodes from tenant control planes. Providers retain centralized control over scheduling, placement, and resource exposure, while tenants interact with a clean, Kubernetes-native API.
This abstraction simplifies operations and enables advanced scheduling strategies without leaking infrastructure complexity or constraints into the customer experience.
vCluster templates enable neoclouds to offer one-click AI clusters with standardized configurations, policies, and integrations. GPU-enabled environments can be provisioned instantly and consistently, turning infrastructure into a repeatable product rather than a bespoke deployment.
At the orchestration layer, vCluster integrates with any GPU scheduler. This allows providers to evolve scheduling strategies, performance guarantees, and cost controls independently of tenant control planes. GPU behavior becomes schedulable, measurable, and supportable, which is critical for AI-focused customers.
Launching a Kubernetes cluster is rarely the hard part. You can build or partner depending on your requirements. The real challenge begins once that cluster is in production, and the ecosystem keeps moving beneath you as you deal with day 2 operations.
For this part, you need to think about how operational maturity matters more than initial setup.
Kubernetes ships three releases every year. Each one introduces version skew, API deprecations, security fixes, and shifting best practices. For neoclouds, maintaining deep Kubernetes expertise in-house is difficult, especially when platform teams are also responsible for building core infrastructure, product differentiation, and go-to-market execution.
Beyond the initial setup, teams quickly encounter the realities of Day 2 operations and incident response. This is where operational complexity compounds and where most platforms start to feel the strain.
Once customers are onboarded, Kubernetes operations become continuous work. Staying current requires upgrade planning, validating compatibility across add-ons, and proactively addressing deprecated APIs before they break workloads.
As scale increases, so does the burden. More clusters, more tenants, more configuration variance, and higher customer expectations all amplify operational risk. At this stage, operational maturity matters far more than how quickly the first cluster was launched. Customer experience is defined by predictable upgrades, consistent reliability, and repeatable fleet operations, not by the initial provisioning flow.
In production environments, incidents are not hypothetical. Kubernetes failure modes include control plane performance degradation, etcd pressure, networking and DNS issues, node instability, storage behavior, and upgrade regressions.
When something goes wrong, customers expect fast triage, clear ownership, and a credible escalation path. Many neoclouds discover that building a reliable on-call rotation, operational runbooks, and incident playbooks takes significantly longer than building the first version of the service itself. Trust is not earned by avoiding incidents, but by responding to them well.
vCluster, in addition to its features and platform, brings a team who has hard-earned operational experience from building and supporting Kubernetes across a wide range of real-world environments. We have helped customers from banks, telecoms and other neoclouds to improve their overall strategy for resilience.
Instead of learning Day 2 operations under pressure, neoclouds can partner with a team that already has proven patterns for upgrades, fleet operations, and incident response.
This shifts Kubernetes from a risky internal initiative into a launchable, supportable product with a clear path to operational stability.
For neoclouds, especially those at bronze maturity or below, the fastest path to a credible managed Kubernetes offering is accelerating time-to-market without taking on full operational risk.
Partnering with vCluster enables three practical outcomes: launching a managed Kubernetes offering in weeks, receiving architecture guidance from day one, and having operational and incident escalation support when production realities hit.
This shortens the path from service launch to revenue while avoiding the cost and risk of building everything alone.
Overall, you just don’t get a better experience for your customers, but more recognition. Learn more about How vCluster Helps You Meet ClusterMAX™ Kubernetes Expectations
Early architectural decisions determine whether a platform scales cleanly or accumulates long-term operational debt. vCluster has seen a lot of architectures go right and, more importantly, go wrong. It positions us in a position where we can help with architecture guidance grounded in real deployments, including Neocloud and GPU-focused environments.
This helps teams make informed decisions around isolation boundaries, multi-tenancy models, networking design, and sizing assumptions from the start. The result is a platform that is easier to upgrade, more resilient under load, and cheaper to operate over time.
Operating managed Kubernetes is a long-term commitment, not a one-time project. You need a partner who can help to keep pace with Kubernetes evolution through structured support matrices, upgrade guidance, and hands-on operational backing as fleets grow.
When incidents occur, vCluster from our experience provides a clear support and escalation path that enables faster recovery and protects customer trust. The outcome is a managed Kubernetes experience that is easier to operate, easier to scale, and far more resilient to ecosystem changes than building on your own.
For neoclouds, success is ultimately defined by speed, confidence, and focus.
The fastest path to revenue comes from delivering a managed Kubernetes offering that customers trust from day one. That trust is built on secure access, clear isolation, safe upgrades, reliable observability, and predictable GPU behavior, not on feature depth alone. Neoclouds that succeed bring these guarantees to market quickly, without spending a year building and hardening foundational platform components.
What makes this possible is not shortcuts, but maturity. The platform foundation behind vCluster is the result of more than five years of focused engineering investment. The hard problems have already been solved, refined, and battle tested across real production environments. Today, that accumulated R and D allows new environments to be stood up in days, not months, with enterprise grade isolation and operational safeguards built in from the start.
Customers recognize this maturity immediately. As one might put it, it is clear this platform was not assembled overnight. It reflects years of iteration and deep Kubernetes expertise. Instead of inheriting risk, teams inherit a proven stack they can use out of the box with confidence.
Equally important is focus. Winning teams do not tie up their best engineers rebuilding Kubernetes primitives. They invest in core differentiation, AI infrastructure, pricing models, and customer experience. By building on a foundation that has already absorbed years of engineering effort, neoclouds reduce risk, control costs, and preserve engineering capacity for innovation that actually moves the business forward in weeks.
In a market where confidence determines adoption, choosing the right platform foundation is not simply a technical decision. It is a business decision grounded in trust, ecosystem expertise, and long term reliability.
How does vCluster integrate with our existing infrastructure and operational processes?
vCluster runs on your existing Kubernetes infrastructure and integrates with current networking, storage, identity providers, CI/CD pipelines, and GPU schedulers without requiring hardware changes.
What is the migration path for existing workloads or clusters to vCluster?
The migration path is similar to moving workloads between standard Kubernetes clusters. Since vCluster is Kubernetes native, existing manifests, Helm charts, and operators continue to work without modification in most cases. Workloads can be migrated using familiar tools such as Velero for backup and restore, GitOps pipelines for redeployment, or standard CI CD workflows. This allows teams to transition incrementally while maintaining operational consistency and portability.
Can vCluster help us with architecture choices?
Yes, vCluster provides guidance on multi tenancy models, isolation boundaries, networking design, and upgrade strategies based on real world production experience. Our expertise while building Kubernetes has helped many of our customers shape their architecture design for scale.
Can you provide detailed case studies or references from similar NeoCloud providers?
Yes, references and case studies from NeoCloud and GPU focused environments are available to demonstrate operational patterns and production outcomes. Please contact us here.
Deploy your first virtual cluster today.