How vCluster Auto Nodes Delivers Dynamic Kubernetes Scaling Across Any Infrastructure

Sep 9, 2025
|
4
min Read

Tenancy requirements don’t stop at isolation — they evolve with elasticity. A team that starts with dedicated GPU nodes today may need those same resources to scale on demand tomorrow. Another may burst between private datacenter hardware during working hours and public cloud GPUs overnight.
vCluster is expanding the definition of Kubernetes tenancy to meet these dynamic needs. With the release of vCluster v0.28 and vCluster Platform v4.4, building on our v0.27 release of Private Nodes. Let’s dive deeper!
Autoscaling solutions are often tied to vendor infrastructure. When you consider available solutions like cluster autoscaler, they support scaling but are bound to the host cluster and struggle with hybrid or multi-cloud environments. Cloud-specific options like EKS Auto Mode simplify operations but reinforce provider lock-in.
Both approaches either waste resources or increase complexity: static provisioning leads to costly over-provisioning, resource waste, and slow response to demand spikes, while hybrid and multi-cloud strategies increase cluster sprawl and overhead.
The ideal solution should let organizations select hardware based on cost and efficiency. This means using private cloud resources when available and seamlessly shifting workloads to public cloud capacity during demand spikes or other optimization patterns. This requires elasticity without added complexity, security trade-offs, or vendor lock-in.
With vCluster v0.28 and vCluster Platform v4.4, Auto Nodes address this gap. By directly integrating Karpenter, the open-source workload-aware node provisioning engine with vCluster, you expand Kubernetes tenancy beyond static infrastructure.
Auto Nodes enables intelligent, dynamic provisioning of private nodes across any environment without vendor lock-in. They combine strong isolation with provider-agnostic elasticity, functioning across environments from hyperscalers to bare metal. Now you get secure tenancy and cloud-native elasticity — no brittle scripts, no wasted over-provisioning, just dynamic scaling where and when you need it in a cloud-agnostic fashion.
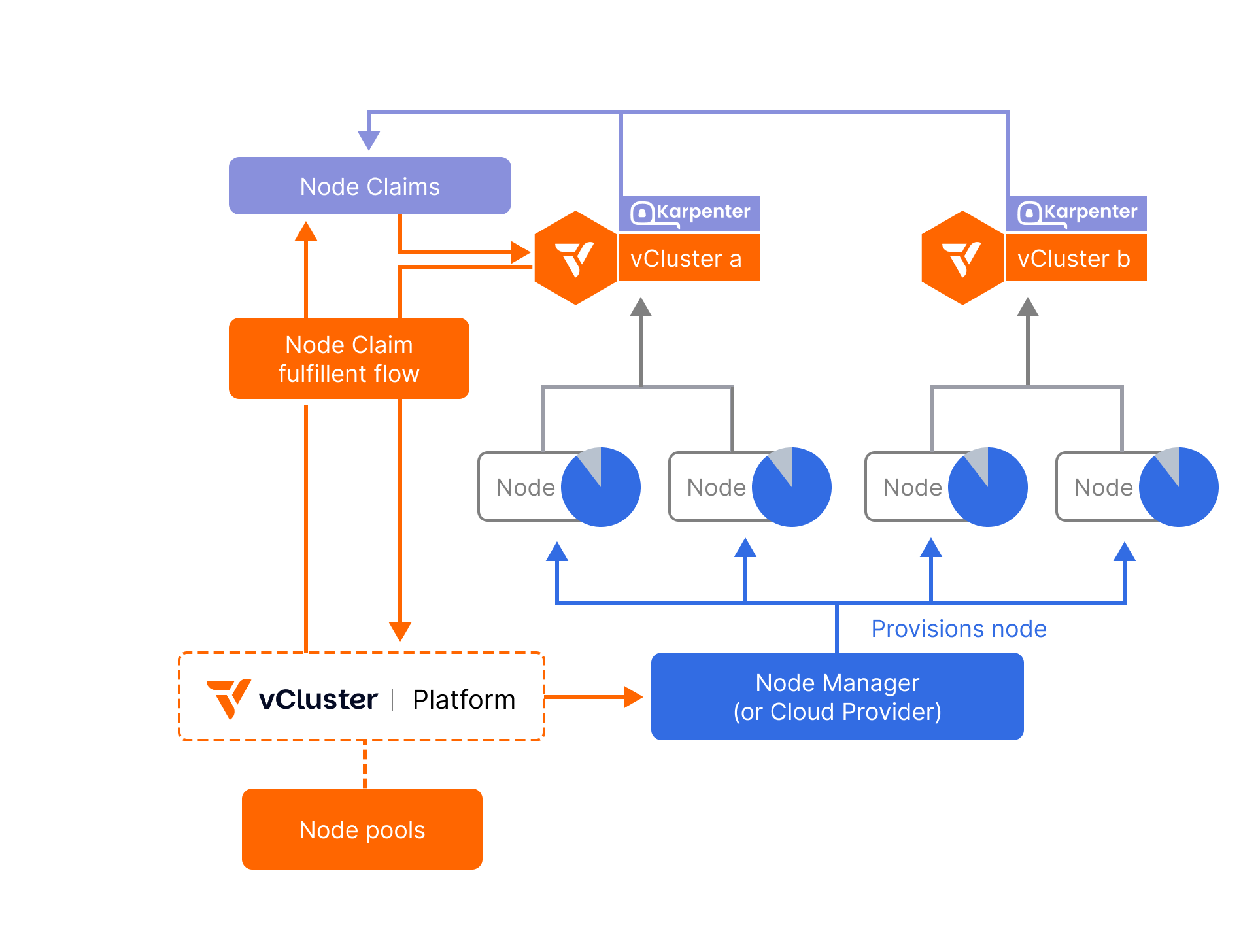
It works by defining “node providers” once and letting vCluster provision provider-agnostic private nodes. Currently, three node providers are supported, which can be used to create CPU, GPU, VM-based, and custom node types:
The vCluster Terraform provider, powered by OpenTofu, enables seamless provisioning of Auto Nodes: when your workloads powered by auto nodes need capacity, a Terraform script (inline or sourced from Git) triggers to dynamically create the required infrastructure. Scripts run using OpenTofu, with full context passed through the var.vcluster object, including cluster name, namespace, user data, node claims, and custom properties.
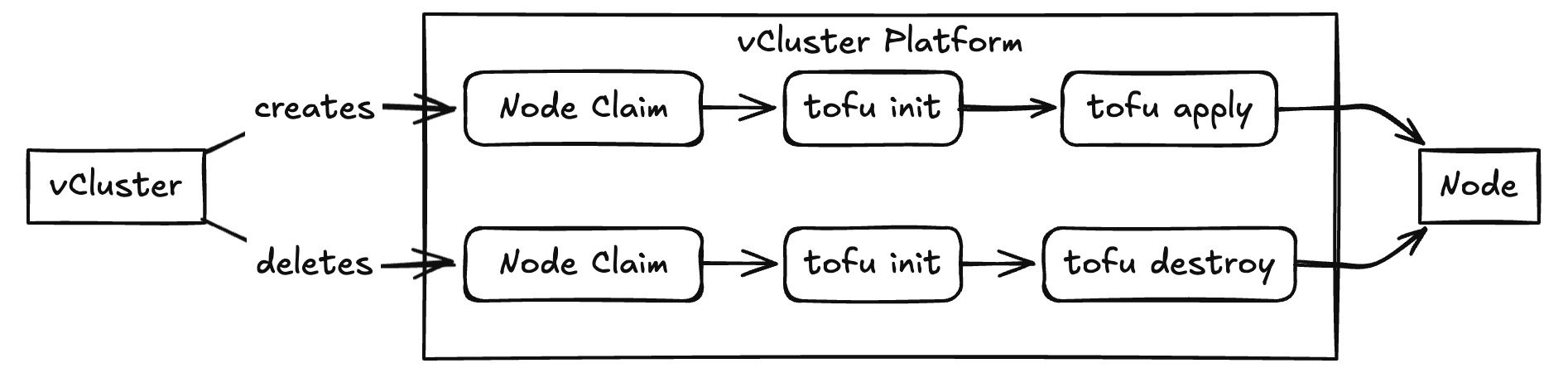
The node types allow fine-grained resource control (like CPU, memory, region), with optional maxCapacity to limit scale.
Many private cloud environments are built around GPU stacks, with NVIDIA Base Command Manager (BCM) being the most widely used layer for managing NVIDIA GPUs. With Auto Nodes, you also have support for BCM, making it easy to create GPU Private Nodes in vCluster. This enables elastic, workload-aware provisioning of isolated GPU capacity across your DGX nodes.
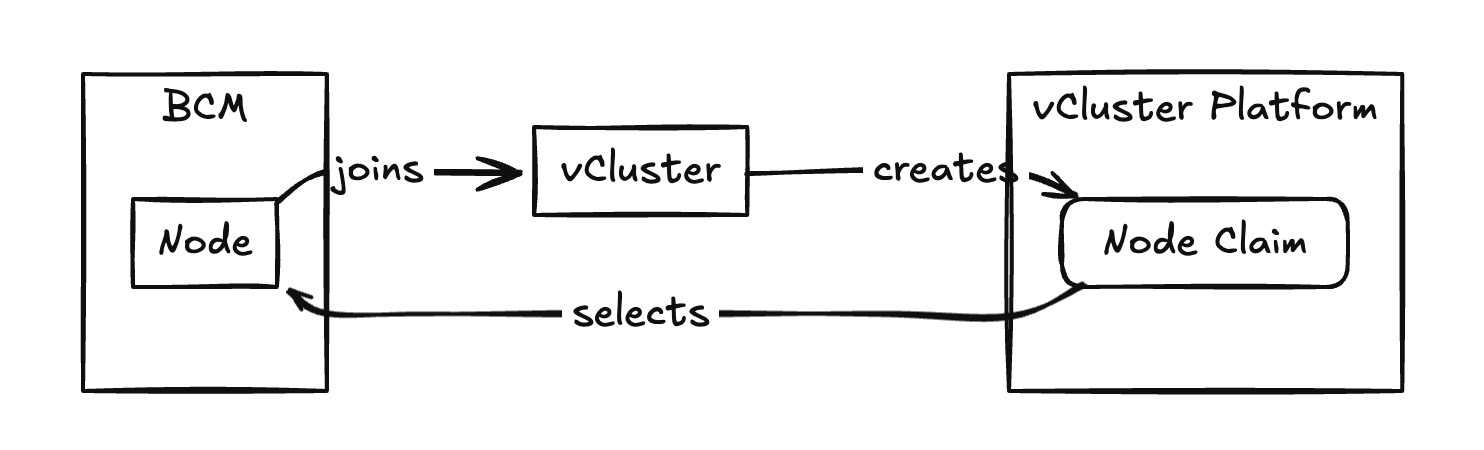
The BCM provider gives vCluster a direct interface to dynamically spin up GPU nodes whenever workloads demand them. This ensures efficient utilization by reducing idle GPU costs, preventing over-provisioning, and eliminating lock-in from unused resources.
A common requirement is to run virtual machines, and while KubeVirt is the best approach, autoscaling across providers can be challenging. The KubeVirt provider enables vCluster to provision VMs as dynamic nodes, offering flexible “flavors” of compute, such as small, medium, large, or even with different operating systems, all managed from a central configuration in the vCluster Platform.

With flexible customization and automatic registration via cloud-init, vCluster makes it simple to run diverse workloads with full isolation and lifecycle automation.
In addition to these options, you can also create a custom NodeProvider for any regulated or niche environment.
When a workload is deployed into a vCluster, pods that can’t immediately find a home are flagged as unschedulable. This is where the embedded Karpenter operator comes into play. Karpenter continuously monitors these unscheduled pods and springs into action by creating NodeClaims — requests for new nodes that can satisfy the workload’s specific resource needs.
The NodeClaims are then passed along to the NodeProviders, which define how and where nodes get created. A NodeProvider might be backed by Terraform or other providers that we saw before. This flexibility ensures that workloads can land on the right type of infrastructure, whether in the cloud, in your datacenter, or on bare metal.
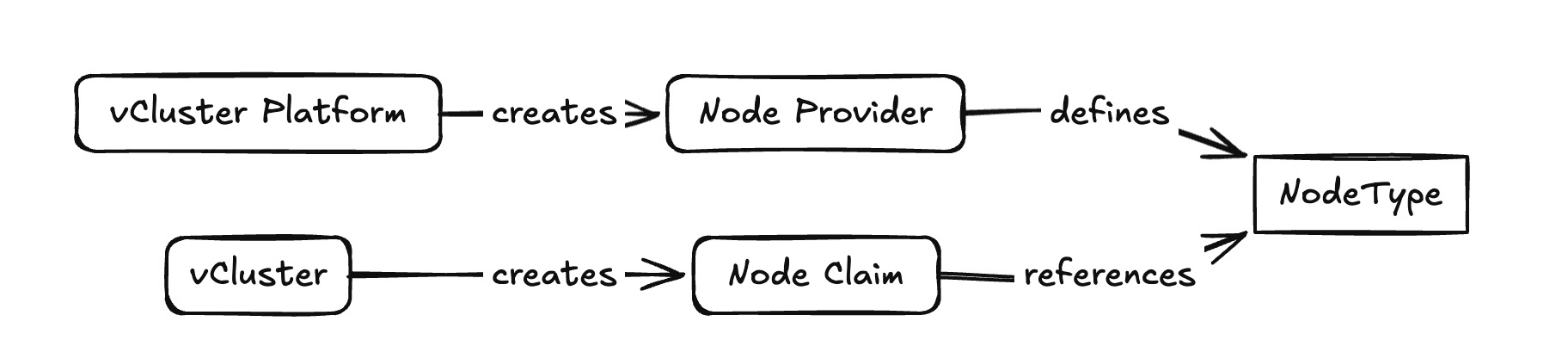
Each NodeProvider can expose multiple NodeTypes, and this is where fine-grained control comes in. NodeTypes encapsulate the node’s shape, cost preferences, capacity limits, and properties like CPU architecture or GPU availability. You declare them in YAML, which lets you define both static pools (always available) and dynamic pools (provisioned only when workloads demand them) as below:
# Inside your vcluster.yaml
privateNodes:
enabled: true
autoNodes:
static:
- name: my-static-pool
requirements:
# Exact match
- property: my-property
value: my-value
# One of
- property: my-property
operator: In
values: ["value-1", "value-2", "value-3"]
# Not in
- property: my-property
operator: NotIn
values: ["value-1", "value-2", "value-3"]
# Exists
- property: my-property
operator: Exists
# NotExists
- property: my-property
operator: NotExists
Karpenter evaluates these options and selects the most efficient and cost-effective match for each NodeClaim. The result is just-in-time provisioning. Auto Nodes deliver exactly the infrastructure needed, when it’s needed, while factoring in costs, topology, and workload requirements. And just as importantly, they scale back down when demand drops. Idle nodes are reclaimed automatically, keeping your footprint lean and your costs in check.
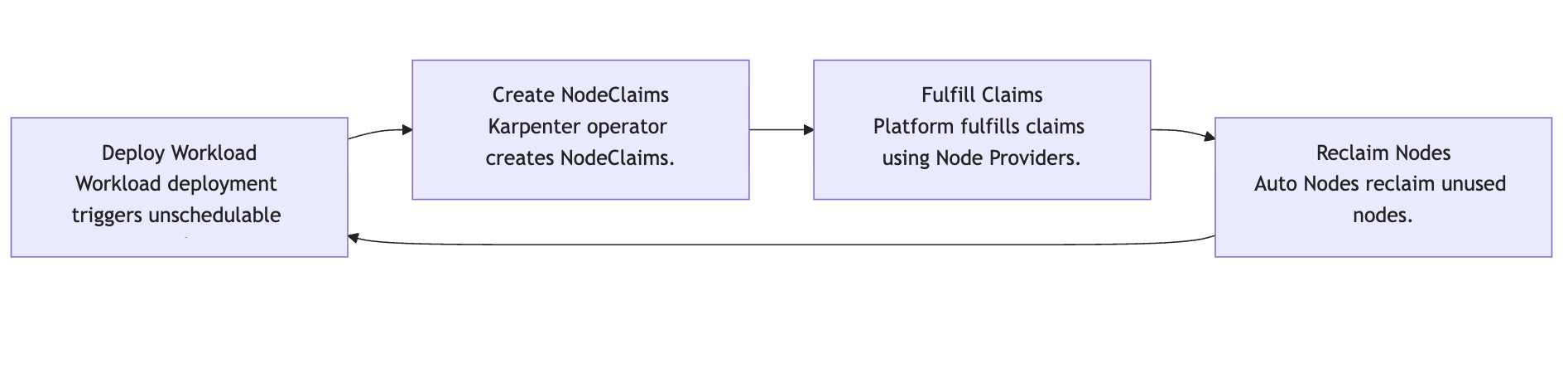
In practice, this means you get the elasticity of the cloud, but it is applied consistently across any environment without vendor lock-in. Auto Nodes take the guesswork and scripting out of scaling, letting your clusters run smarter, leaner, and more securely.
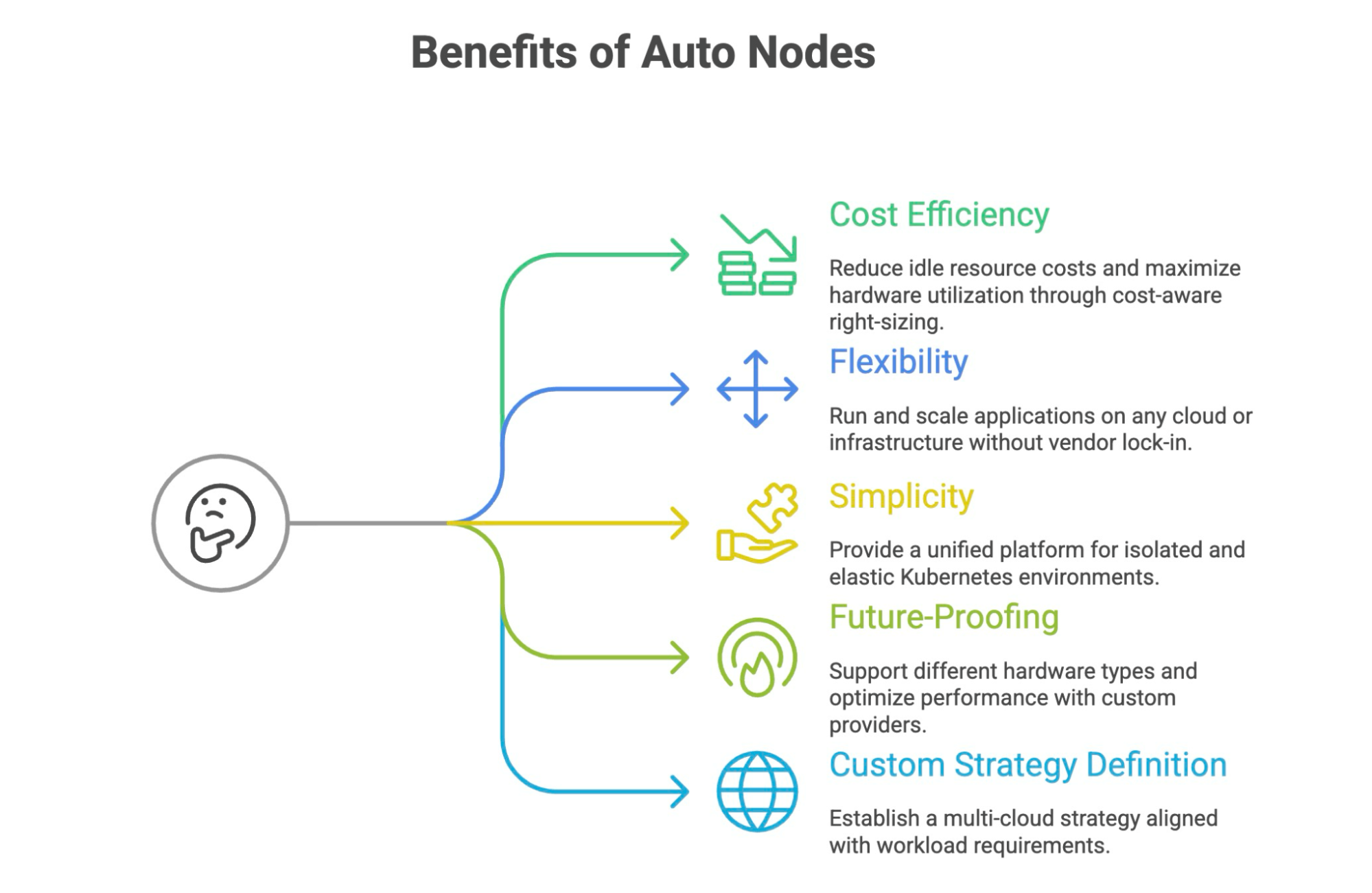
As you dive deeper, you may question how this benefits you. There are many ways, but the five most important areas where implementing auto nodes can help are categorized as follows:
The main advantage is that platform teams can reduce idle resource costs while maximizing hardware utilization through direct access to hardware. The vCluster Platform offers cost-aware right-sizing that automatically balances performance and cost considerations.
To configure this, you can add explicit costs or derive them from resource specifications while taking into account any discounts, such as volume usage discounts. Auto Nodes will assess the cost function to deliver optimal cost-performance ratios.
This approach allows you to achieve maximum hardware usage while sizing resources based on cost and requirements, ultimately saving on both infrastructure usage and scaling costs.
The goal of any organization is to run applications on any cloud or infrastructure without being locked into a specific vendor. With auto nodes, you can not only run your applications but also scale them effectively on the infrastructure of your choice. Additionally, the platform utilizes label-like properties combined with set-based operators (such as In, NotIn, Exists, and NotExists) to enable precise node selection.
For example, using built-in properties like vcluster.com/node-type and topology.kubernetes.io/zone makes targeting straightforward and intuitive.
With the providers, your developers can be assured of having a unified platform for isolated and elastic Kubernetes environments, without having to worry about application logic, cost, or performance. Auto Nodes request capacity through NodeClaims, while Karpenter matches these requests to compatible node types and continuously right-sizes the fleet.
The system automatically prioritizes the most cost-effective eligible options and supports a variety of workloads, including CPU, GPU, VM-based, and custom resources like nvidia.com/gpu. Resources are securely gated so that expensive hardware, such as GPUs, is only provisioned when workloads explicitly request them.
As your team expands to support different hardware types, you can create custom providers to meet evolving infrastructure demands. To optimize performance, you can set maximum capacity limits (maxCapacity) for each node type for KubeVirt and Terraform providers. The BCM provider goes further and supports automatic detection of these limits.
vCluster monitors usage patterns and helps prevent over-scheduling for future optimization, so your workloads run with sufficient resources. For example, the system creates lazy-loaded node environments, automatically provisioning prerequisites such as VPCs through Terraform when necessary, with one-time Node Environments created for each vCluster.
A significant amount of procurement is done through Savings Plans, Reserved Instances (RIs), and Spot Instances for compute services. Additionally, some organizations utilize private cloud solutions. It is crucial to consider these options when defining your strategy. With Auto Nodes, you can easily establish a multi-cloud strategy that aligns with your workload requirements.
For example, you can start by scaling your workload using your private cloud infrastructure and then automatically transition to the public cloud to handle spikes in capacity when necessary. Another example involves using specific GPU clouds tailored for different GPU types or directing workloads to the most suitable infrastructure based on your business needs and cost considerations.
As you have understood, scaling efficiently without sacrificing flexibility is critical in today's Kubernetes ecosystem. Auto Nodes, powered by Karpenter, bring seamless, infrastructure-agnostic autoscaling directly into your vCluster experience. With this, teams can achieve high scalability, resilience, and cost efficiency levels, without locking themselves into a single vendor or compromising on workload isolation.
Whether you’re building a SaaS platform, running dynamic GPU workloads, or managing enterprise-scale applications, Auto Nodes ensure that scaling is no longer a trade-off but a built-in superpower.
Deploy your first virtual cluster today.
